
The unrolled representation is shown in <> (similar to <>).
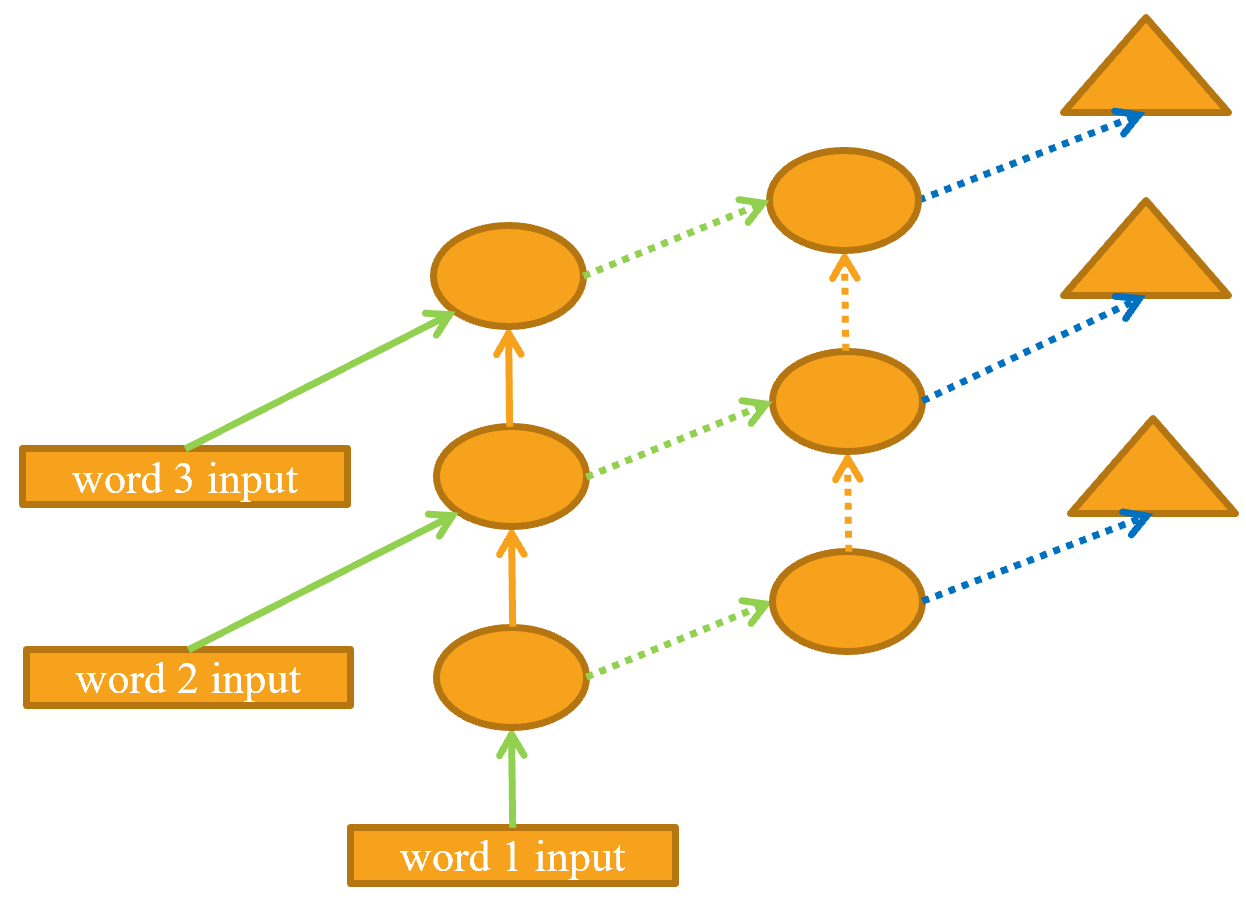
Let’s see how to implement this in practice.
In [ ]:
In [ ]:
learn = Learner(dls, LMModel5(len(vocab), 64, 2),metrics=accuracy, cbs=ModelResetter)
Now that’s disappointing… our previous single-layer RNN performed better. Why? The reason is that we have a deeper model, leading to exploding or vanishing activations.
Exploding or Disappearing Activations
In practice, creating accurate models from this kind of RNN is difficult. We will get better results if we call detach less often, and have more layers—this gives our RNN a longer time horizon to learn from, and richer features to create. But it also means we have a deeper model to train. The key challenge in the development of deep learning has been figuring out how to train these kinds of models.
Because matrix multiplication is just multiplying numbers and adding them up, exactly the same thing happens with repeated matrix multiplications. And that’s all a deep neural network is —each extra layer is another matrix multiplication. This means that it is very easy for a deep neural network to end up with extremely large or extremely small numbers.
This is a problem, because the way computers store numbers (known as “floating point”) means that they become less and less accurate the further away the numbers get from zero. The diagram in <>, from the excellent article , shows how the precision of floating-point numbers varies over the number line.
This inaccuracy means that often the gradients calculated for updating the weights end up as zero or infinity for deep networks. This is commonly referred to as the vanishing gradients or exploding gradients problem. It means that in SGD, the weights are either not updated at all or jump to infinity. Either way, they won’t improve with training.
For RNNs, there are two types of layers that are frequently used to avoid exploding activations: gated recurrent units (GRUs) and long short-term memory (LSTM) layers. Both of these are available in PyTorch, and are drop-in replacements for the RNN layer. We will only cover LSTMs in this book; there are plenty of good tutorials online explaining GRUs, which are a minor variant on the LSTM design.

