
DataX 工具实现跨 TiDB 集群的增量数据复制,是在 TiDB 4.0 的 CDC 工具正式发布前比较成熟的一项选择,有利于在数据中心内统一同异构平台的数据传输工具。
下面会以双 TiDB 集群互为主备的场景为案例进行操作讲解。从设计上既满足了传统数据库运维的要求,生产数据库拥有容灾备库提高系统健壮性,又使得服务器硬件等资源得到了更充分的利用。
方案设计如图所示
具体操作步骤:
第一步:部署DataX
解压
自检
第二步:编辑同步Job
vi increase.json
{"job": {"setting": {"speed": {"channel": 128 #根据业务情况调整Channel数}},"content": [{"reader": {"name": "tidbreader","parameter": {"username": "${srcUserName}","password": "${srcPassword}","column": ["*"],"connection": [{"table": ["${tableName}"],"jdbcUrl": ["${srcUrl}"]}],"where": "updateTime >= '${syncTime}'"}},"writer": {"name": "tidbwriter","parameter": {"username": "${desUserName}","password": "${desPassword}","writeMode": "replace","column": ["*"],"connection": [{"jdbcUrl": "${desUrl}","table": ["${tableName}"]}],"preSql": ["replace into t_sync_record(table_name,start_date,end_date) values('@table',now(),null)"],"postSql": ["update t_sync_record set end_date=now() where table_name='@table' " ]}}}]}}
第三步:编写运行DataX Job的Shell执行脚本
vi datax_excute_job.sh
chmod +x datax_excute_job.sh
DataX Job 的 Shell 执行脚本可以注册在 Supervisor 等服务工具中管理。当双 TiDB 集群需要进行主备切换时,可以做到任务随时启停,正反向同步随时切换。
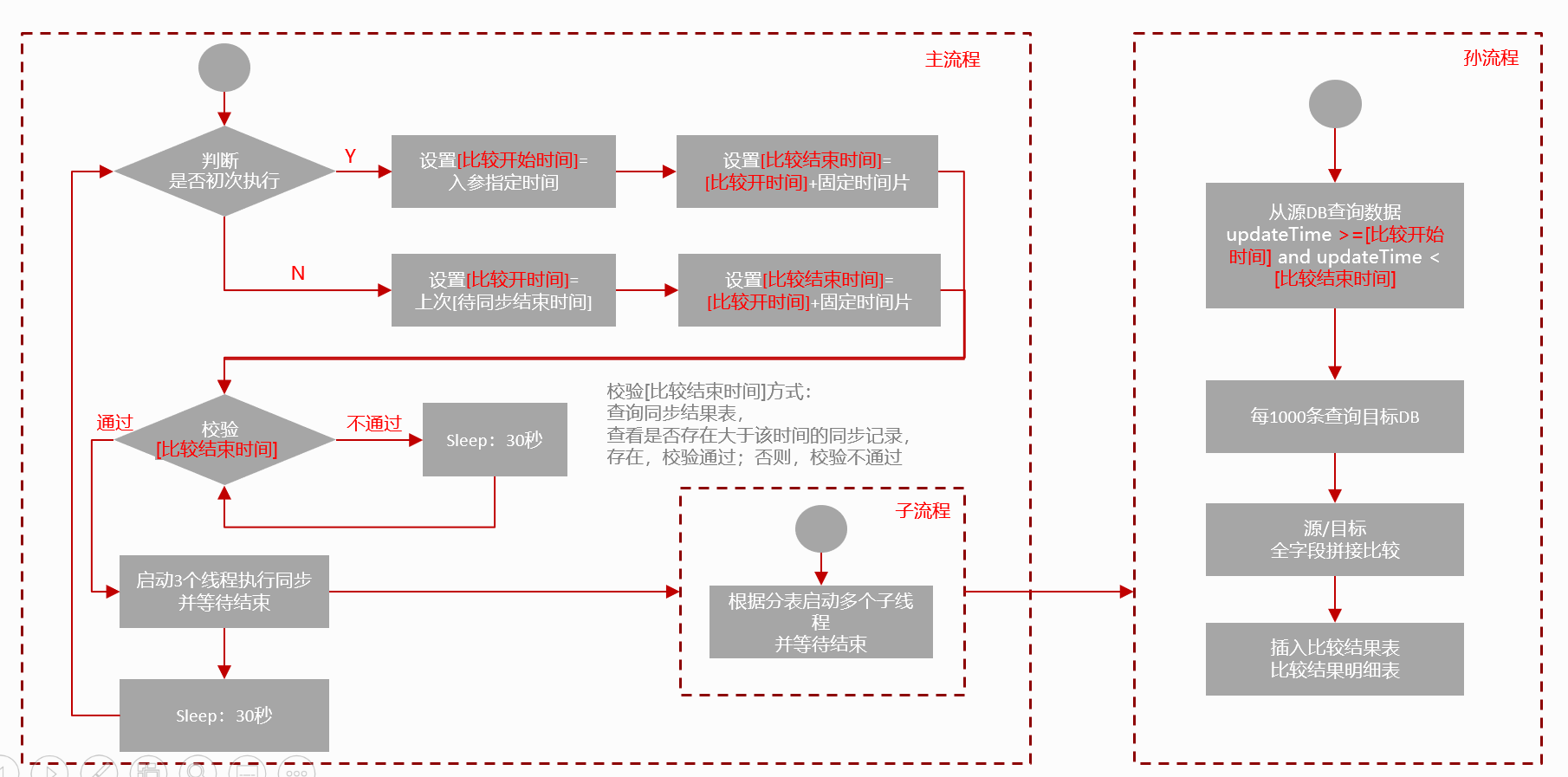
第五步:数据校验服务
按自定义时间跨度查询两个 TiDB 的数据,设置流式读取两个 TiDB 中表数据,转成字符串进行对比,更高效。在比对过程中,为了提高比对效率,如果发现不一致,记录哪张表的哪个时间片有不一致即可,不需要运算定位到具体某一行。对于发现不一致的记录可以发送报警,人工介入处理,也可以调动同步脚本,重新同步一次,可根据自己的业务灵活选择。
简单的数据校验流程可以参考下图。
用DataX 进行双 TiDB 集群间的数据同步不一定是最好的,但每个方案都有其特定存在的场景和意义。如果双集群间广域网链路质量不太稳定,又或者有特殊的定制需求等原因时,可以考虑本方案。

