
这一层的节点都是无状态的,节点本身并不存储数据,节点之间完全对等。
能想到的最简单的方案就是通过上一节所述的 映射方案,将 SQL 查询映射为对 KV 的查询,再通过 KV 接口获取对应的数据,最后执行各种计算。
比如 这样一个语句,我们需要读取表中所有的数据,然后检查 name 字段是否是 TiDB,如果是的话,则返回这一行。具体流程是:
- 构造出 Key Range:一个表中所有的
RowID都在[0, MaxInt64)这个范围内,那么我们用 和MaxInt64根据行数据的Key编码规则,就能构造出一个[StartKey, EndKey)的左闭右开区间 - 扫描 Key Range:根据上面构造出的 Key Range,读取 TiKV 中的数据
- 计算 :对符合要求的每一行,累计到
Count(*)的结果上面
这个方案肯定是可以 Work 的,但是并不能 Work 的很好,原因是显而易见的:
- 在扫描数据的时候,每一行都要通过 KV 操作从 TiKV 中读取出来,至少有一次 RPC 开销,如果需要扫描的数据很多,那么这个开销会非常大
- 符合要求的行的值并没有什么意义,实际上这里只需要有几行数据这个信息就行
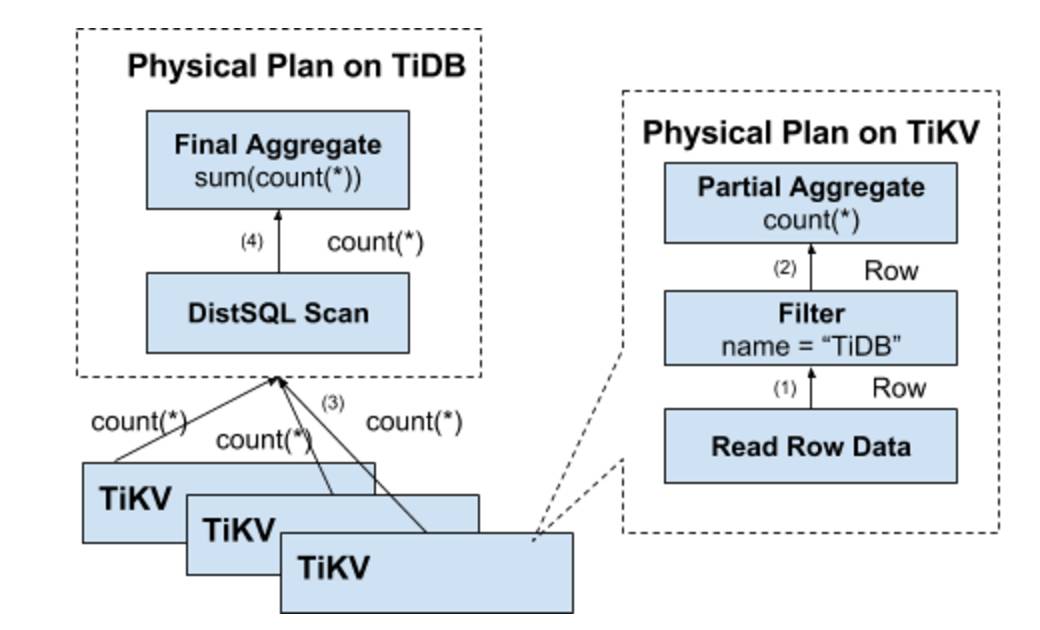
如何避免上述缺陷也是显而易见的,我们需要将计算尽量靠近存储节点,以避免大量的 RPC 调用。首先,我们需要将 SQL 中的谓词条件下推到存储节点进行计算,这样只需要返回有效的行,避免无意义的网络传输。然后,我们还可以将聚合函数 Count(*) 也下推到存储节点,进行预聚合,每个节点只需要返回一个 Count(*) 的结果即可,再由 SQL 层将各个节点返回的 Count(*) 的结果累加求和。
通过上面的例子,希望大家对 SQL 语句的处理有一个基本的了解。实际上 TiDB 的 SQL 层要复杂的多,模块以及层次非常多,下面这个图列出了重要的模块以及调用关系:

