
TDengine 分布式架构的逻辑结构图如下:
图 1 TDengine架构示意图
一个完整的 TDengine 系统是运行在一到多个物理节点上的,逻辑上,它包含数据节点(dnode)、TDengine应用驱动(taosc)以及应用(app)。系统中存在一到多个数据节点,这些数据节点组成一个集群(cluster)。应用通过taosc的API与TDengine集群进行互动。下面对每个逻辑单元进行简要介绍。
物理节点(pnode): pnode是一独立运行、拥有自己的计算、存储和网络能力的计算机,可以是安装有OS的物理机、虚拟机或Docker容器。物理节点由其配置的 FQDN(Fully Qualified Domain Name)来标识。TDengine完全依赖FQDN来进行网络通讯,如果不了解FQDN,请看博文。
数据节点(dnode): dnode 是 TDengine 服务器侧执行代码 taosd 在物理节点上的一个运行实例,一个工作的系统必须有至少一个数据节点。dnode包含零到多个逻辑的虚拟节点(VNODE),零或者至多一个逻辑的管理节点(mnode)。dnode在系统中的唯一标识由实例的End Point (EP )决定。EP是dnode所在物理节点的FQDN (Fully Qualified Domain Name)和系统所配置的网络端口号(Port)的组合。通过配置不同的端口,一个物理节点(一台物理机、虚拟机或容器)可以运行多个实例,或有多个数据节点。
虚拟节点(vnode): 为更好的支持数据分片、负载均衡,防止数据过热或倾斜,数据节点被虚拟化成多个虚拟节点(vnode,图中V2, V3, V4等)。每个 vnode 都是一个相对独立的工作单元,是时序数据存储的基本单元,具有独立的运行线程、内存空间与持久化存储的路径。一个 vnode 包含一定数量的表(数据采集点)。当创建一张新表时,系统会检查是否需要创建新的 vnode。一个数据节点上能创建的 vnode 的数量取决于该数据节点所在物理节点的硬件资源。一个 vnode 只属于一个DB,但一个DB可以有多个 vnode。一个 vnode 除存储的时序数据外,也保存有所包含的表的schema、标签值等。一个虚拟节点由所属的数据节点的EP,以及所属的VGroup ID在系统内唯一标识,由管理节点创建并管理。
虚拟节点组(VGroup): 不同数据节点上的 vnode 可以组成一个虚拟节点组(vnode group)来保证系统的高可靠。虚拟节点组内采取master/slave的方式进行管理。写操作只能在 master vnode 上进行,系统采用异步复制的方式将数据同步到 slave vnode,这样确保了一份数据在多个物理节点上有拷贝。一个 vgroup 里虚拟节点个数就是数据的副本数。如果一个DB的副本数为N,系统必须有至少N个数据节点。副本数在创建DB时通过参数 replica 可以指定,缺省为1。使用 TDengine 的多副本特性,可以不再需要昂贵的磁盘阵列等存储设备,就可以获得同样的数据高可靠性。虚拟节点组由管理节点创建、管理,并且由管理节点分配一个系统唯一的ID,VGroup ID。如果两个虚拟节点的vnode group ID相同,说明他们属于同一个组,数据互为备份。虚拟节点组里虚拟节点的个数是可以动态改变的,容许只有一个,也就是没有数据复制。VGroup ID是永远不变的,即使一个虚拟节点组被删除,它的ID也不会被收回重复利用。
TAOSC: taosc是TDengine给应用提供的驱动程序(driver),负责处理应用与集群的接口交互,提供C/C++语言原生接口,内嵌于JDBC、C#、Python、Go、Node.js语言连接库里。应用都是通过taosc而不是直接连接集群中的数据节点与整个集群进行交互的。这个模块负责获取并缓存元数据;将插入、查询等请求转发到正确的数据节点;在把结果返回给应用时,还需要负责最后一级的聚合、排序、过滤等操作。对于JDBC, C/C++/C#/Python/Go/Node.js接口而言,这个模块是在应用所处的物理节点上运行。同时,为支持全分布式的RESTful接口,taosc在TDengine集群的每个dnode上都有一运行实例。
通讯方式:TDengine系统的各个数据节点之间,以及应用驱动与各数据节点之间的通讯是通过TCP/UDP进行的。因为考虑到物联网场景,数据写入的包一般不大,因此TDengine 除采用TCP做传输之外,还采用UDP方式,因为UDP 更加高效,而且不受连接数的限制。TDengine实现了自己的超时、重传、确认等机制,以确保UDP的可靠传输。对于数据量不到15K的数据包,采取UDP的方式进行传输,超过15K的,或者是查询类的操作,自动采取TCP的方式进行传输。同时,TDengine根据配置和数据包,会自动对数据进行压缩/解压缩,数字签名/认证等处理。对于数据节点之间的数据复制,只采用TCP方式进行数据传输。
FQDN配置:一个数据节点有一个或多个FQDN,可以在系统配置文件taos.cfg通过参数“fqdn”进行指定,如果没有指定,系统将自动获取计算机的hostname作为其FQDN。如果节点没有配置FQDN,可以直接将该节点的配置参数fqdn设置为它的IP地址。但不建议使用IP,因为IP地址可变,一旦变化,将让集群无法正常工作。一个数据节点的EP(End Point)由FQDN + Port组成。采用FQDN,需要保证DNS服务正常工作,或者在节点以及应用所在的节点配置好hosts文件。
端口配置:一个数据节点对外的端口由TDengine的系统配置参数serverPort决定,对集群内部通讯的端口是serverPort+5。集群内数据节点之间的数据复制操作还占有一个TCP端口,是serverPort+10. 为支持多线程高效的处理UDP数据,每个对内和对外的UDP连接,都需要占用5个连续的端口。因此一个数据节点总的端口范围为serverPort到serverPort + 10,总共11个TCP/UDP端口。(另外还可能有 RESTful、Arbitrator 所使用的端口,那样的话就一共是 13 个。)使用时,需要确保防火墙将这些端口打开,以备使用。每个数据节点可以配置不同的serverPort。
集群对外连接: TDengine集群可以容纳单个、多个甚至几千个数据节点。应用只需要向集群中任何一个数据节点发起连接即可,连接需要提供的网络参数是一数据节点的End Point(FQDN加配置的端口号)。通过命令行CLI启动应用taos时,可以通过选项-h来指定数据节点的FQDN, -P来指定其配置的端口号,如果端口不配置,将采用TDengine的系统配置参数serverPort。
集群内部通讯: 各个数据节点之间通过TCP/UDP进行连接。一个数据节点启动时,将获取mnode所在的dnode的EP信息,然后与系统中的mnode建立起连接,交换信息。获取mnode的EP信息有三步,1:检查mnodeEpSet文件是否存在,如果不存在或不能正常打开获得mnode EP信息,进入第二步;2:检查系统配置文件taos.cfg, 获取节点配置参数firstEp, secondEp,(这两个参数指定的节点可以是不带mnode的普通节点,这样的话,节点被连接时会尝试重定向到mnode节点)如果不存在或者taos.cfg里没有这两个配置参数,或无效,进入第三步;3:将自己的EP设为mnode EP, 并独立运行起来。获取mnode EP列表后,数据节点发起连接,如果连接成功,则成功加入进工作的集群,如果不成功,则尝试mnode EP列表中的下一个。如果都尝试了,但连接都仍然失败,则休眠几秒后,再进行尝试。
新数据节点的加入:系统有了一个数据节点后,就已经成为一个工作的系统。添加新的节点进集群时,有两个步骤,第一步:使用TDengine CLI连接到现有工作的数据节点,然后用命令”create dnode”将新的数据节点的End Point添加进去; 第二步:在新的数据节点的系统配置参数文件taos.cfg里,将firstEp, secondEp参数设置为现有集群中任意两个数据节点的EP即可。具体添加的详细步骤请见详细的用户手册。这样就把集群一步一步的建立起来。
重定向:无论是dnode还是taosc,最先都是要发起与mnode的连接,但mnode是系统自动创建并维护的,因此对于用户来说,并不知道哪个dnode在运行mnode。TDengine只要求向系统中任何一个工作的dnode发起连接即可。因为任何一个正在运行的dnode,都维护有目前运行的mnode EP List。当收到一个来自新启动的dnode或taosc的连接请求,如果自己不是mnode,则将mnode EP List回复给对方,taosc或新启动的dnode收到这个list, 就重新尝试建立连接。当mnode EP List发生改变,通过节点之间的消息交互,各个数据节点就很快获取最新列表,并通知taosc。
为解释vnode, mnode, taosc和应用之间的关系以及各自扮演的角色,下面对写入数据这个典型操作的流程进行剖析。
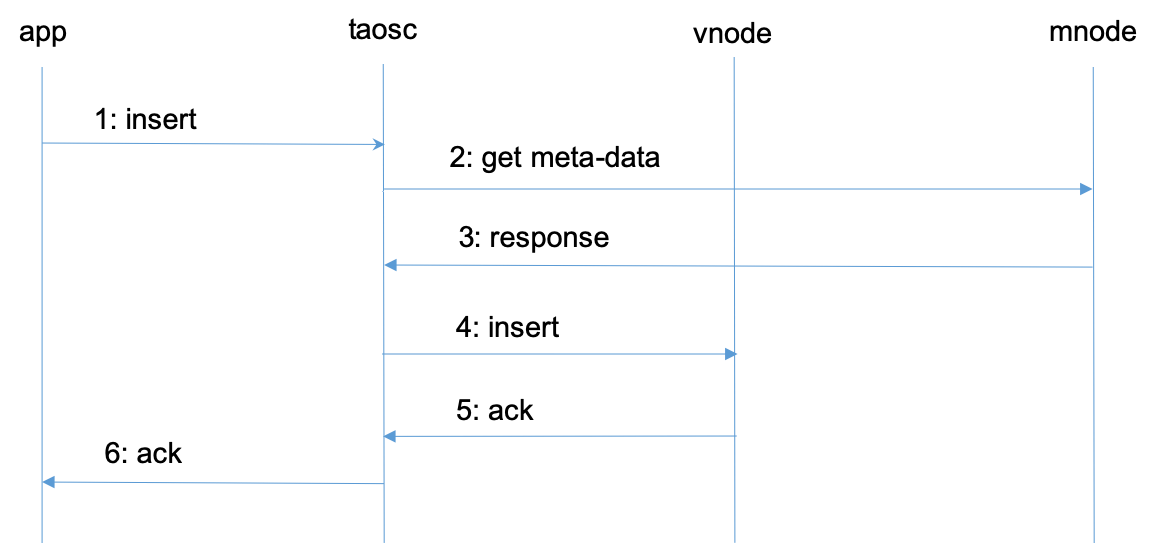
图 2 TDengine典型的操作流程
- 应用通过JDBC、ODBC或其他API接口发起插入数据的请求。
- taosc会检查缓存,看是否保存有该表的meta data。如果有,直接到第4步。如果没有,taosc将向mnode发出get meta-data请求。
- taosc向master vnode发起插入请求。
- vnode插入数据后,给taosc一个应答,表示插入成功。如果taosc迟迟得不到vnode的回应,taosc会认为该节点已经离线。这种情况下,如果被插入的数据库有多个副本,taosc将向vgroup里下一个vnode发出插入请求。
对于第二和第三步,taosc启动时,并不知道mnode的End Point,因此会直接向配置的集群对外服务的End Point发起请求。如果接收到该请求的dnode并没有配置mnode,该dnode会在回复的消息中告知mnode EP列表,这样taosc会重新向新的mnode的EP发出获取meta-data的请求。
对于第四和第五步,没有缓存的情况下,taosc无法知道虚拟节点组里谁是master,就假设第一个vnodeID就是master,向它发出请求。如果接收到请求的vnode并不是master,它会在回复中告知谁是master,这样taosc就向建议的master vnode发出请求。一旦得到插入成功的回复,taosc会缓存master节点的信息。
通过taosc缓存机制,只有在第一次对一张表操作时,才需要访问mnode,因此mnode不会成为系统瓶颈。但因为schema有可能变化,而且vgroup有可能发生改变(比如负载均衡发生),因此taosc会定时和mnode交互,自动更新缓存。

