
对比测试的测试程序和数据库服务在同一台4核8GB的Dell台式机上部署,台式机型号为OptiPlex-3050,详细配置如下
测试数据集及其生成方法
本次测试调研了两类比较热门的测试数据集
- 纽约出租车运行数据,因该数据中抹去了单台车辆的信息,无法对其进行建模
- faker生成工具,因其只能生成字符串,并不适合物联网场景下处理的数据
所以,为使测试可轻易重复,单独编写了一个生成模拟数据的程序来进行本次测试。
测试数据生成程序模拟若干温湿度计生成的数据,其中温度为整数、湿度为浮点数,同时每个温度计包含设备ID、设备分组、设备名称三个标签。为了尽可能真实地模拟温湿度计的生成数据,没有使用完全随机数,而是针对每个温度计确保生成的数据值呈正态分布。
测试数据的频率为1秒钟,数据集包含10000台设备,每台设备10000条记录。每条数据采集记录包含1个时间戳字段、2个数据字段和3个标签字段。
2.测试数据生成程序源码
采用java程序生成测试数据集,测试程序源代码可以到https://github.com/taosdata/TDengine/tree/master/tests/comparisonTest/dataGenerator下载,下载后执行如下语句
3.测试数据生成程序用法
相关参数如下
- dataDir 生成的数据文件路径
- numOfFiles 生成的数据文件数目
- numOfDevices 测试数据集中的设备数目
- rowsPerDevice 测试数据集中每台设备包含的记录条数
4.生成测试数据
执行如下命令,会在~/testdata目录下生成100个数据文件,每个文件包含100台设备的测试数据;合计10000台设备,每台设备10000条记录
mkdir ~/testdatajava com/taosdata/generator/DataGenerator -dataDir ~/testdata -numOfDevices 10000 -numOfFiles 100 -rowsPerDevice 10000
TDengine环境准备
TDengine是一个开源的专为物联网、车联网、工业互联网、IT运维等设计和优化的大数据平台。除核心的快10倍以上的时序数据库功能外,还提供缓存、数据订阅等功能,最大程度减少研发和运维的工作量。
1.安装部署
- 下载tdengine-1.6.1.0.tar.gz,地址
- 安装TDengine,解压后运行install.sh进行安装
- 启动TDengine,运行sudo systemctl start taosd
- 测试是否安装成功,运行TDengine的shell命令行程序taos,可以看到如下类似信息
Welcome to the TDengine shell, server version:1.6.1.0 client version:1.6.1.0Copyright (c) 2017 by TAOS Data, Inc. All rights reserved.
2.数据建模
TDengine为相同结构的设备创建一张超级表,而每个具体的设备则单独创建一张数据表。因此,超级表的数据字段为采集时间、温度、湿度等与时间序列相关的采集数据;标签字段为设备编号、设备分组编号、设备名称等设备本身固定的描述信息。
创建超级表的SQL语句为
create table devices(ts timestamp, temperature int, humidity float) tags(devid int, devname binary(16), devgroup int);
以设备ID作为表名(例如device id为1,则表名为dev1),使用自动建表语句,写入一条记录的语句为
insert into dev1 using devices tags(1,'d1',0) values(1545038786000,1,3.560000);
3.测试程序源码
本文采用TDengine的原生C语言接口,编写数据写入及查询程序,后续的其他文章会提供基于JDBCDriver的测试程序。
测试程序源代码及查询SQL语句可以到https://github.com/taosdata/TDengine/tree/master/tests/comparisonTest/tdengine下载,下载后执行如下语句
cd tdenginemake
会在当前目录下生成可执行文件./tdengineTest
TDengine的测试程序用法与InfluxDB的用法相同,写入相关参数
- writeClients 并发写入的客户端链接数目,默认为1
- rowsPerRequest 一次请求中的记录条数,默认为100,范围1-1000
- dataDir 读取的数据文件路径,来自于测试数据生成程序
- numOfFiles 从数据文件路径中读取的文件个数
例如
./tdengineTest -dataDir ./data -numOfFiles 10 -writeClients 2 -rowsPerRequest 100
查询相关参数
- sql 将要执行的SQL语句列表所在的文件路径,以逗号区分每个SQL语句
例如
./tdengineTest -sql ./sqlCmd.txt
InfluxDB环境准备
InfluxDB是一款开源的时序数据库,由Go语言实现。适用于监控、实时分析、物联网、传感器数据等应用场景,是目前最为流行的时间序列数据库。
1.安装部署
- 下载并安装InfluxDB
wget https://dl.influxdata.com/influxdb/releases/influxdb_1.7.7_amd64.debsudo dpkg -i influxdb_1.7.7_amd64.deb
- 启动InfluxDB服务
sudo systemctl start influxdb
- 测试是否安装成功,运行InfluxDB的shell命令行程序influx,可以看到如下类似信息
Connected to http://localhost:8086 version 1.7.7InfluxDB shell version: 1.7.7>
2.InfluxDB数据建模
创建一个名为devices的measurement,所有设备都属于该measurement,不同设备通过标签进行区分。每台设备包含三个标签,分别为设备编号、设备分组编号、设备名称。每条记录包含三个数据字段,分别为时间戳(毫秒),温度(整型),湿度(浮点)。
3.InfluxDB测试程序源码
本文采用InfluxDB的原生GO语言接口,编写数据写入及查询程序,测试程序源代码及查询SQL语句可以到下载。下载后需要先安装GO语言环境。
然后执行如下语句
cd tests/comparisonTest/influxdbgo build -o influxdbTest
会在当前目录下生成可执行文件./influxdbTest
4.InfluxDB测试程序用法
写入相关参数
- writeClients 并发写入的客户端链接数目,默认为1
- rowsPerRequest 一次请求中的记录条数,默认为100,范围1-1000
- dataDir 读取的数据文件路径,来自于测试数据生成程序
- numOfFiles 从数据文件路径中读取的文件个数
例如
./influxdbTest -dataDir ~/testdata -numOfFiles 1 -writeClients 2 -rowsPerRequest 100
查询相关参数
- sql 将要执行的SQL语句列表所在的文件路径,以逗号区分每个SQL语句
例如
./influxdbTest -sql ./sqlCmd.txt
数据库的一个写入请求可以包含一条或多条记录,一次请求里包含的记录条数越多,写入性能就会相应提升。在以下测试中,使用R/R表示Records/Request ,即一次请求中的记录条数。同时,一个数据库可以支持多个客户端连接,连接数增加,系统总的写入通吐量也会相应增加。因此测试中,对于每一个数据库,都会测试一个客户端和多个客户端连接的情况。
1.TDengine的写入性能
TDengine按照每次请求包含1,100,500,1000,2000条记录各进行测试,同时也测试了不同客户端连接数的情况。测试步骤如下所示,您可以修改示例中的参数,完成多次不同的测试。
运行TDengine的shell命令行程序taos,执行删除测试数据库语句Welcome to the TDengine shell, server version:1.6.1.0 client version:1.6.1.0Copyright (c) 2017 by TAOS Data, Inc. All rights reserved.taos>drop database db;2.测试执行开启5个客户端读取~/testdata目录中的100个数据文件,每个请求写入1000条数据,可以参考如下命令./tdengineTest -dataDir ~/testdata -numOfFiles 100 -writeClients 5 -rowsPerRequest 1000
写入吞吐量如下,单位为记录数/秒
图1 TDengine的写入吞吐量
2.InfluxDB的写入性能
写入吞吐量如下,单位为记录数/秒
| R/R | 1 client | 2 clients | 3 clients | 4 clients | 5 clients | 6 clients | 7 clients |
|---|---|---|---|---|---|---|---|
| 1 | 31 | 43 | 55 | 67 | 80 | 92 | 106 |
| 100 | 3024 | 4325 | 5709 | 6819 | 8013 | 9204 | 10173 |
| 1000 | 21940 | 30659 | 40825 | 50622 | 60567 | 70311 | 77174 |
| 10000 | 88686 | 155154 | 209377 | 234124 | 245141 | 257454 | 261542 |
| 20000 | 96277 | 179492 | 234413 | 255805 | 263160 | 268466 | 271249 |
| 50000 | 125187 | 200552 | 243861 | 264780 | 271101 | 270364 | 273820 |
| 100000 | 130108 | 197202 | 240059 | 254973 | 265922 | 272275 | 270859 |
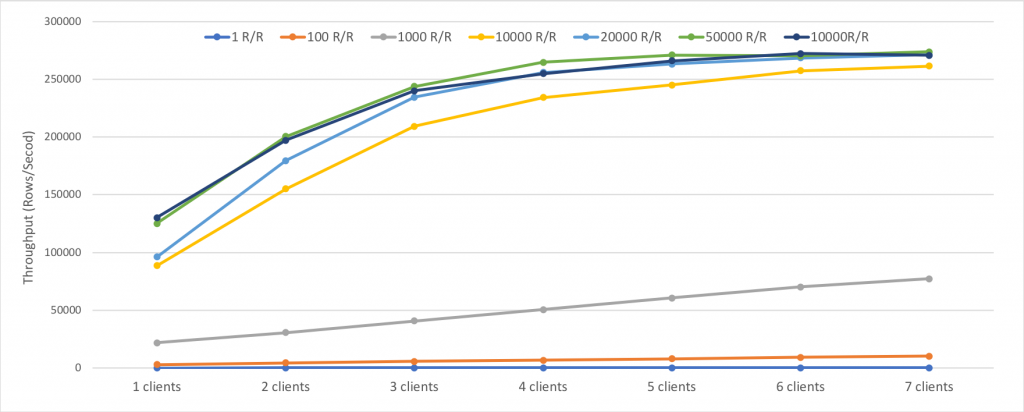
图2 InfluxDB的写入吞吐量
基于以上的测试数据,将TDengine和InfluxDB测试出的最佳写入速度进行对比,结果如下
| R/R | 1 client | 2 clients | 3 clients | 4 clients | 5 clients | 6 clients | 7 clients |
|---|---|---|---|---|---|---|---|
| TDengine | 512820 | 1055520 | 1174164 | 1306904 | 1426635 | 1458434 | 1477208 |
| InfluxDB | 130108 | 200552 | 243861 | 264780 | 271101 | 272275 | 273820 |
图3 TDengine和InfluxDB的最佳写入性能对比
从图3可以看出,TDengine的写入速度约为百万条记录/秒的量级,而InfluxDB的写入速度约为十万条记录/秒的量级。因此可以得出结论,在同等数据集和硬件环境下,TDengine的写入速度远高于InfluxDB,约为5倍。
需要指出的是,InfluxDB的单条插入性能很低,因此必须采用Kafka或其他消息队列软件,成批写入,这样增加了系统开发和维护的复杂度与运营成本。
读取性能对比
本测试做了简单的遍历查询,就是将写入的数据全部读出。因为InfluxDB的GO客户端在解析JSON返回结果时的限制,故每次查询仅取出100万条记录。在测试数据准备时,已经按照devgroup标签将设备拆分成100个分组,本次测试随机选取其中10个分组进行查询。
1.TDengine的测试方法
测试SQL语句存储在tdengine/q1.txt中,测试SQL语句参考select * from db.devices where devgroup=0;执行方法如下
2.InfluxDB的测试方法
测试SQL语句存储在influxdb/q1.txt中,测试SQL语句参考select * from devices where devgroup='0';执行方法如下./influxDBTest -sql ./q1.txt
如下所示,横轴为设备分组编号,测试结果的单位为秒
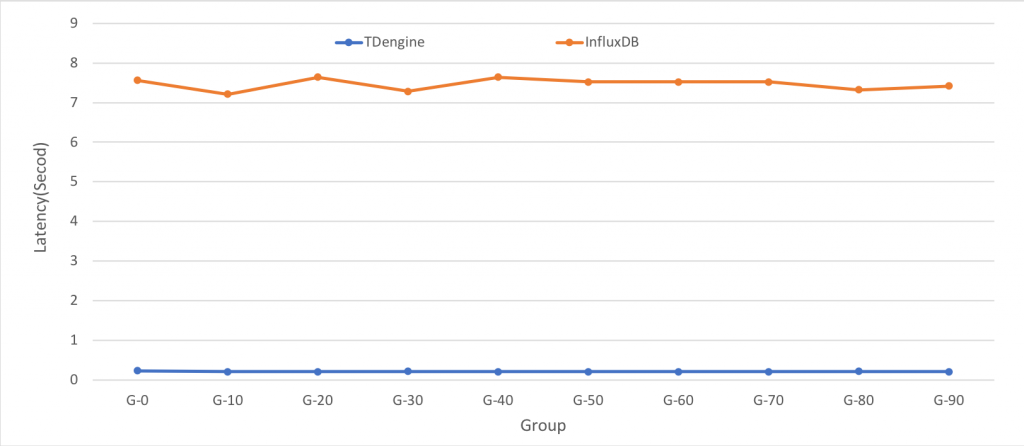
图4 TDengine和InfluxDB的读取性能对比
从图4中可以看出,TDengine的100万条的读取速度稳定在0.21秒,吞吐量约为500万条记录/秒,InfluxDB的100万条的读取速度稳定在7.5秒,吞吐量约为13万条记录/秒。所以从测试结果来看,TDengine的查询吞吐量远高于InfluxDB。
聚合函数性能对比
本单元的测试包含COUNT,AVERAGE,SUM,MAX,MIN,SPREAD这六个TDEngine和InfluxDB共有的聚合函数。所有测试函数都会搭配筛选条件(WHERE)来选取设备的十分之一、十分之二、十分之三、直到全部设备。
1.TDengine的聚合函数性能
测试SQL语句存储在tdengine/q2.txt中,测试SQL语句参考
select count(*) from db.devices where devgroup<10;
执行方法如下
./tdengineTest -sql ./q2.txt
如下所示,横轴为查询设备占总设备的百分比,测试结果的单位为秒
| 10% | 20% | 30% | 40% | 50% | 60% | 70% | 80% | 90% | 100% | |
|---|---|---|---|---|---|---|---|---|---|---|
| count | 0.018 | 0.026 | 0.016 | 0.018 | 0.017 | 0.024 | 0.024 | 0.027 | 0.030 | 0.033 |
| avg | 0.007 | 0.014 | 0.015 | 0.020 | 0.024 | 0.038 | 0.044 | 0.050 | 0.057 | 0.060 |
| sum | 0.006 | 0.010 | 0.019 | 0.018 | 0.031 | 0.036 | 0.034 | 0.037 | 0.043 | 0.046 |
| max | 0.007 | 0.013 | 0.015 | 0.020 | 0.025 | 0.030 | 0.035 | 0.039 | 0.045 | 0.049 |
| min | 0.006 | 0.010 | 0.016 | 0.024 | 0.032 | 0.039 | 0.045 | 0.041 | 0.043 | 0.049 |
| spread | 0.007 | 0.010 | 0.015 | 0.019 | 0.033 | 0.038 | 0.046 | 0.052 | 0.059 | 0.066 |
图5 TDengine聚合函数性能
2.InfluxDb的聚合函数性能
测试SQL语句存储在influxdb/q2.txt中。因为InfluxDB的标签仅能为字符串,所以测试SQL语句的筛选条件为正则表达式,如下的SQL语句选取第10-19个group中的数据,例如
select count(*) from devices where devgroup=~/[1-1][0-9]/;
执行方法如下
./influxdbTest -sql ./q2.txt
如下所示,横轴为查询设备占总设备的百分比,测试结果的单位为秒
| 10% | 20% | 30% | 40% | 50% | 60% | 70% | 80% | 90% | 100% | |
|---|---|---|---|---|---|---|---|---|---|---|
| count | 1.06 | 2.14 | 3.28 | 4.15 | 5.26 | 6.19 | 7.01 | 8.09 | 9.06 | 9.92 |
| mean | 0.99 | 2.05 | 2.77 | 3.68 | 4.51 | 5.35 | 6.14 | 6.95 | 7.70 | 8.44 |
| sum | 1.02 | 2.04 | 2.89 | 3.75 | 4.64 | 5.50 | 6.38 | 7.18 | 7.94 | 8.72 |
| max | 1.01 | 1.99 | 2.85 | 3.77 | 4.69 | 5.52 | 6.35 | 7.17 | 7.95 | 8.80 |
| min | 1.03 | 2.02 | 2.95 | 3.81 | 4.64 | 5.48 | 6.33 | 7.18 | 8.01 | 8.72 |
| spread | 7.38 | 16.92 | 27.44 | 38.25 | 49.86 | 60.68 | 71.61 | 82.50 | 94.68 | 105.26 |
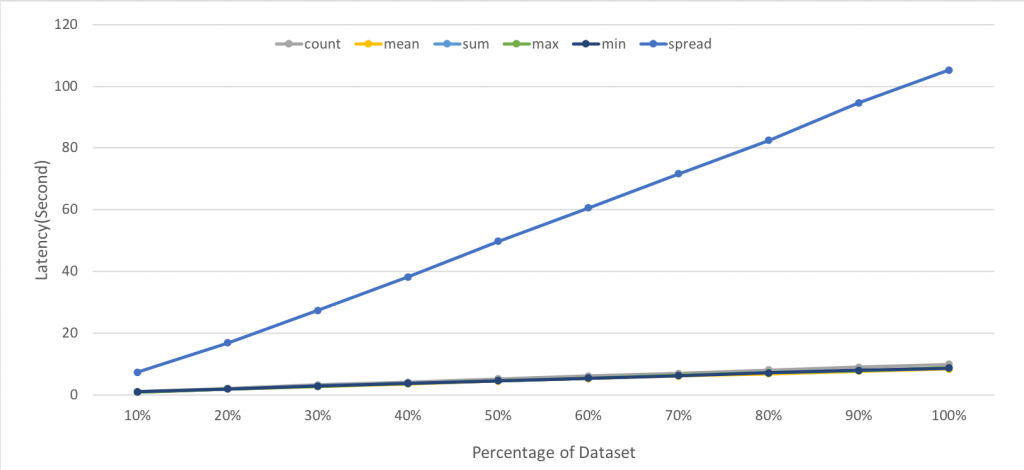
图6 InfluxDB聚合函数性能
3.聚合函数性能对比
基于以上的测试数据,将TDengine和InfluxDB在1亿条记录数据集的测试结果进行对比
图7 聚合函数性能对比
从图7可以看出,TDengine的聚合函数查询时间在100毫秒以内,而InfluxDb的查询时间在10秒左右。因此可以得出结论,在同等数据集和硬件环境下,TDengine聚合函数的查询速度远远高于InfluxDB,超过100倍。
按标签分组查询性能对比
本测试做了按标签分组函数的性能测试,测试函数会搭配筛选条件(WHERE)来选取设备的十分之一、十分之二、十分之三、直到全部设备。
1.TDengine的测试方法
测试SQL语句存储在tdengine/q3.txt中,例如
./tdengineTest -sql ./q3.txt
2.InfluxDB的测试方法
测试SQL语句存储在influxdb/q3.txt中,例如
select count(temperature), sum(temperature), mean(temperature) from devices where devgroup=~/[1-1][0-9]/ group by devgroup;
执行方法如下
./influxdbTest -sql ./q3.txt
如下所示,横轴为查询设备占总设备的百分比,测试结果的单位为秒
| 10% | 20% | 30% | 40% | 50% | 60% | 70% | 80% | 90% | 100% | |
|---|---|---|---|---|---|---|---|---|---|---|
| TDengine | 0.030 | 0.028 | 0.031 | 0.041 | 0.069 | 0.066 | 0.077 | 0.091 | 0.102 | 0.123 |
| InfluxDB | 3.19 | 6.37 | 9.60 | 12.95 | 15.93 | 19.16 | 22.05 | 25.20 | 28.06 | 31.52 |
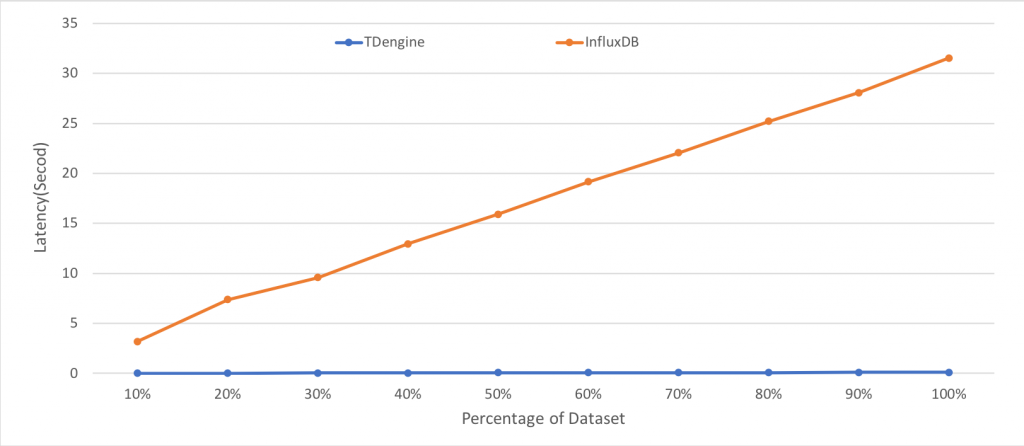
图8 TDengine和InfluxDB的按标签分组查询性能对比
从测试结果来看,TDengine的分组聚合查询速度远高于InfluxDB,约为300倍。
本测试做了按时间分组函数的性能测试,测试函数会搭配筛选条件(WHERE)来选取设备的十分之一、十分之二、十分之三、直到全部设备。
1.TDengine的测试方法
测试SQL语句存储在tdengine/q4.txt中,例如
select count(temperature), sum(temperature), avg(temperature) from db.devices where devgroup<10 interval(1m);
执行方法如下
./tdengineTest -sql ./q4.txt
2.InfluxDB的测试方法
测试SQL语句存储在influxdb/q4.txt中,例如
select count(temperature), sum(temperature), mean(temperature) from devices where devgroup=~/[1-1][0-9]/ group by time(1m);
执行方法如下
./influxdbTest -sql ./q4.txt
如下所示,横轴为查询设备占总设备的百分比,测试结果的单位为秒
| 10% | 20% | 30% | 40% | 50% | 60% | 70% | 80% | 90% | 100% | |
|---|---|---|---|---|---|---|---|---|---|---|
| TDengine | 0.237 | 0.472 | 0.653 | 0.902 | 1.134 | 1.422 | 1.753 | 1.784 | 2.085 | 2.549 |
| InfluxDB | 3.26 | 6.50 | 9.59 | 12.85 | 16.07 | 19.02 | 22.32 | 25.44 | 28.29 | 31.44 |
图9 TDengine和InfluxDB的按时间分组查询性能对比
从测试结果来看,TDengine的分组聚合查询速度远高于InfluxDB,约为12倍。
压缩比对比
1.原始数据的磁盘占用
本次测试共生成100个测试数据文件,存储在~/testdata目录下,使用du命令查看~/testdata目录的文件大小
cd ~/testdatadu -m .
如下图所示

图10 原始数据的磁盘占用情况
2.查看TDengine的磁盘占用
TDengine的磁盘文件默认位置在目录/var/lib/taos/data下,在查看磁盘文件大小时,首先将TDengine的服务停止
sudo systemctl stop taosd
然后,调用du命令,查看/var/lib/taos/data目录下文件的大小
cd /var/lib/taos/datadu -h .
图11 TDengine的磁盘占用情况
3.查看InfluxDB的磁盘占用
InfluxDB的磁盘文件默认位置在目录/var/lib/influxdb/data/db下,在查看磁盘文件大小时,首先将InfluxDB的服务停止
目录/var/lib/taos/data为用户influxdb所有,请确保当前用户有查看该目录的权限。本测试中,数据存储在autogen/84目录下,调用du命令,查看该目录下文件的大小。
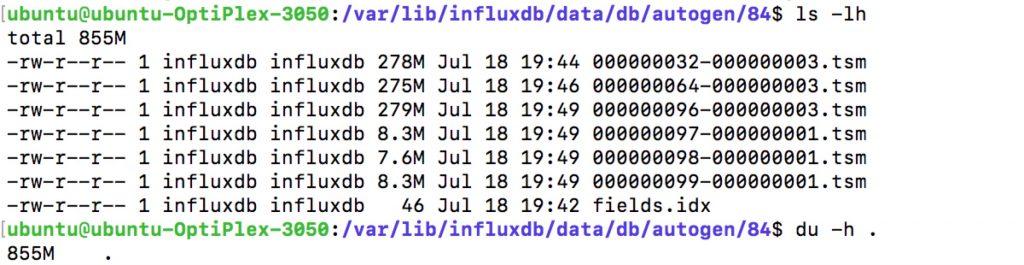
图12 InfluxDB的磁盘占用情况
生成的测试数据文件占用的磁盘大小为3941MB,InfluxDB磁盘占用855MB,TDengine磁盘占用459MB。在相对比较随机数据集的情况下,TDengine的压缩比约为InfluxDB压缩比的1.86倍。
在物联网场景下,大多数采集数据的变化范围都比较小。由于TDengine采用列式存储,因此可以预期,TDengine在真实场景的压缩比表现会更好。
功能对比
TDengine与InfluxDB都能用于时序数据的处理,两者在数据库层面上功能接近。但TDengine还具备消息队列、缓存、消息订阅等大数据平台所需要的功能。使用InfluxDB,还需要集成Kafka, Redis或其他类似软件。具体对比如下:
总结
从测试结果上看,TDengine的性能远超InfluxDB,写入性能约为5倍,读取性能约为35倍,聚合函数性能约为140倍,按标签分组查询性能约为250倍,按时间分组查询性能约为12倍,压缩比约为1.8倍,具体见下表
| TDengine | InfluxDB | |
|---|---|---|
| 写入吞吐量 | 1477208 记录数/秒 | 273820 记录数/秒 |
| 100万条记录读取时间 | 0.21秒 | 7.5秒 |
| 1亿条记录取平均值时间 | 0.06秒 | 8.44秒 |
| 1亿条记录按标签分组取均值时间 | 0.123秒 | 31.52秒 |
| 1亿条记录按时间分组取均值时间 | 2.549秒 | 31.44秒 |
| 1亿条记录的磁盘占用空间 | 459MB | 855MB |

