The demonstration consists of two experiments: a single-node failure simulation, where one node is taken offline, and then a two-node failure, where two TiKV nodes are simultaneously taken offline. In both failures, the cluster repairs itself by re-replicating missing data to other nodes, and you can see how the cluster continues running uninterrupted.
The process is as follows:
Before the process of failure simulation begins, the following requirements are already met:
- has been installed (v1.5.2 or later) as described in TiKV in 5 Minutes.
- has been installed. It is used to interact with the TiKV cluster.
Use the command to start a six-node local TiKV cluster:
The output of this command will show the components’ addresses. These addresses will be used in the following steps.
Start pd instanceStart tikv instanceStart tikv instanceStart tikv instanceStart tikv instanceStart tikv instanceStart tikv instancePD client endpoints: [127.0.0.1:2379]To view the Prometheus: http://127.0.0.1:44549To view the Grafana: http://127.0.0.1:3000
Each Region has three replicas according to the default configuration.
Step 2. Import data to TiKV
Start a new terminal session, and use go-ycsb to launch a workload of writing data to the TiKV cluster.
Clone
go-ycsbfrom GitHub.git clone https://github.com/pingcap/go-ycsb.git
Build the application from the source.
Load a workload using
go-ycsbwith 10000 keys into the TiKV cluster.The expected output is as follows:
Run finished, takes 11.722575701sINSERT - Takes(s): 11.7, Count: 10000, OPS: 855.2, Avg(us): 18690, Min(us): 11262, Max(us): 61304, 99th(us): 36000, 99.9th(us): 58000, 99.99th(us): 62000
Step 3: Verify the data import
Use the client-py tool to verify the data imported in the last step. Note that the Python 3.5+ REPL environment is required for such verification. It is expected that the key count in the output matches the recordcount in the go-ycsb command in the previous step.
>>> from tikv_client import RawClient>>> client = RawClient.connect("127.0.0.1:2379")>>> len(client.scan_keys(None, None, 10000))
The evaluation of the last expression should be 10000, as the recordcount has been specified in the go-ycsb command.
simulates multiple client connections and performs a mix of reads (50%) and writes (50%) per connection.
./bin/go-ycsb run tikv -P workloads/workloada -p tikv.pd="127.0.0.1:2379" -p tikv.type="raw" -p tikv.conncount=16 -p threadcount=16 -p recordcount=10000 -p operationcount=1000000
Per-operation statistics are printed to the standard output every second.
This workload above runs for several minutes, which is enough to simulate a node failure described as follows.
Step 2. Check the workload on Grafana dashboard
Open the dashboard by accessing http://127.0.0.1:3000 in your browser.
Log in the dashboard by using the default username
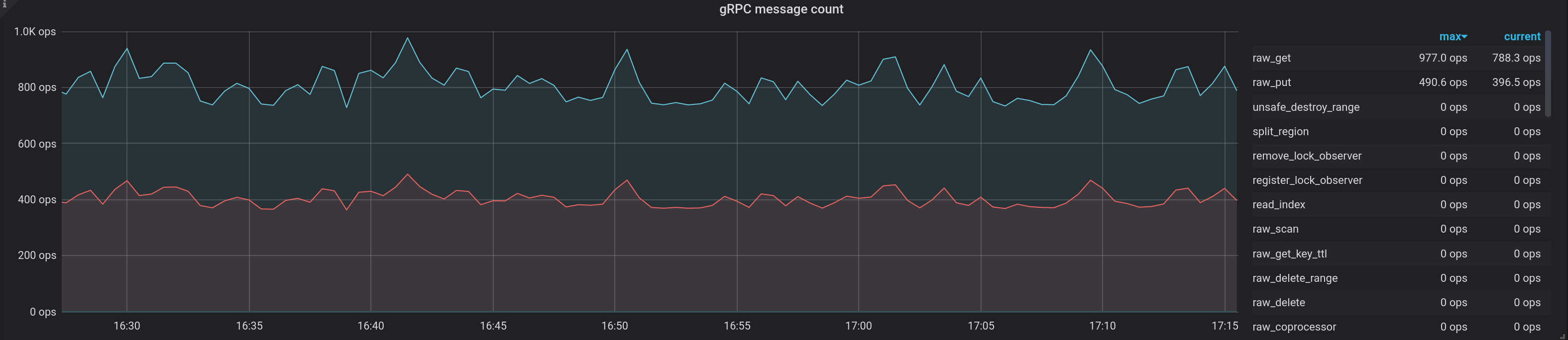
adminand passwordadmin.Enter the dashboard playground-tikv-summary, and the OPS information is in the panel gRPC message count in the row gRPC.
By default, TiKV replicates all data three times and balances the load across all stores. To see this balancing process, enter the page playground-overview and check the Region count across all nodes. In this example, a small amount of data is loaded. Thus only one Region is shown:


Step 1: Stop the target process
In TiKV, all read/write operations are handled by the leader of the Region group. See for details.
In this example, the only one leader in the cluster is stopped. Then the load continuity and cluster health are checked.
Enter the Grafana dashboard playground-overview. The leader distribution is shown in the panel leader in row TiKV.
In this example, the local process that opens the port
20180holds only one leader in the cluster. Execute the following command to stop this process.kill -STOP $(lsof -i:20180 | grep tikv | head -n1 | awk '{print $2}')
Check the gRPC OPS. The monitoring metric shows that there is a short duration in which the TiKV instance is unavailable because the leader is down. However, the workload is back online as soon as the leader election is completed.
Step 1: Stop the target processes
In the above single-node failure simulation, the TiKV cluster has recovered. The leader of the cluster has been stopped, so there are five stores alive. Then, a new leader is elected after a while.
Experiment 2 will increase the Region replicas of TiKV to five, stop two non-leader nodes simultaneously, and check the cluster status.
The component version should be explicitly specified in the tiup ctl command. In the following example, the component version is v6.1.0.
Increase the replicas of the cluster to five:
tiup ctl:v6.1.0 pd config set max-replicas 5
Stop two non-leader nodes simultaneously. In this example, the processes that hold the ports
20181and20182are stopped. The process IDs (PIDs) are1009934and109941.kill -STOP 1009934kill -STOP 1009941
Step 2: Check the load continuity and cluster health on Grafana dashboard
Similar to in the single-node failure simulation, enter the Grafana dashboard and follow playground-tikv-summary -> gRPC -> gRPC message count. The metrics show that the workload continuity is not impacted because the leader is still alive.
To further verify the load continuity and cluster health, is used to read and write some data to prove that the cluster is still available.
After experiment 2 is finished, you might need to clean up the test cluster. To do that, take the following steps:
Go back to the terminal session that you have just started the TiKV cluster and press ctrl + c and wait for the cluster to stop.
-
tiup clean --all

{kind=link}