
迈向深度学习
为了更加清晰地解释这个问题,我们假设数十年后神经网络引发了人工智能(AI)。到那个时候,我们能明白这种智能网络的工作机制吗?可能的情况是,我们还是不能够理解它的原理,不能够理解其中的权重和偏置代表的意义,因为它们是自动学习得到的。在人工智能的早期研究阶段,人们希望在构建人工智能的努力过程中,也同时能够帮助我们理解智能背后的机制,以及人类大脑的运转方式。但最终的结果可能是我们既不能够理解大脑的机制,也不能够理解人工智能的机制。
为了解决这些问题,让我们回想一下我在这章开始对人工神经元作出的解释——它是一种对输入的evidence进行权衡的工具。假设我们想要确定一张图片里是否有人脸:
 .jpg)
.jpg)
1 感谢:1. 2.未知 3.NASA,ESA,G.Illingworth,D. Magee,P. Oesch(加利福尼亚大学,圣克鲁兹),R. Bouwens(莱顿大学)和HUDF09团队。点击图片获取更多信息。
假设我们就采取了这个方法,但接下来我们先不去使用学习算法,而是去尝试人工设计一个网络,并为它选择合适的权重和偏置。我们要怎样做呢?首先暂时忘掉神经网络。一个想法是,我们可以将这个问题分解成一些子问题:图像的左上角有一个眼睛吗?右上角有一个眼睛吗?中间有一个鼻子吗?下面中央有一个嘴吗?上面有头发吗?诸如此类。
如果这些问题的回答是「是的」,或者甚至仅仅是「可能是」,那么我们可以作出结论这个图像可能是一张脸。相反地,如果大多数这些问题的答案是「不是」,那么这张图像可能不是一张脸。
当然,这仅仅是一个粗略的想法,而且它存在许多缺陷。也许有个人是秃头,没有头发。也许我们仅仅能看到部分脸,或者这张脸不是正面的,因此一些面部特征是模糊的。不过这个想法表明了如果我们能够使用神经网络来解决这些子问题,那么我们也许可以通过将这些解决子问题的网络结合起来,构成一个面部检测的神经网络。下图是一个可能的结构,子网络用矩阵来表示。注意,这不是一个人脸识别问题的现实的解决方法;而是用它来帮助我们构建起网络工作方式的直觉。下图是这个网络的结构:
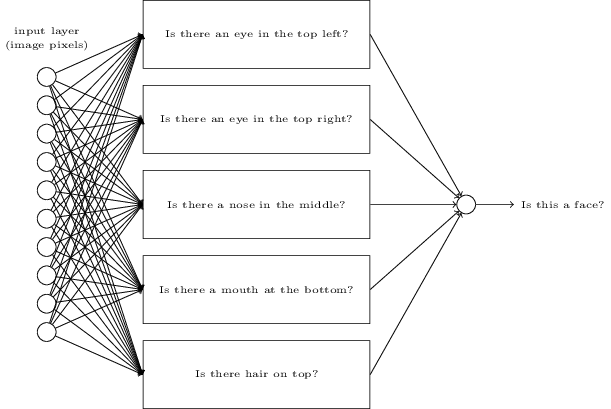
我们还可以对这些子问题的子问题继续进行分解,并通过多层网络传递得越来越远。最终,我们的子网络可以回答那些只包含若干个像素点的简单问题。举例来说,这些简单的问题可能是询问图像中的几个像素是否构成非常简单的形状。这些问题就可以被那些与图像中原始像素点直接相连的单个神经元所回答。
最终的结果是,我们设计出了一个网络,它将一个非常复杂的问题——这张图像是否有一张人脸——分解成在单像素层面上就可回答的非常简单的问题。在前面的网络层,它回答关于输入图像非常简单明确的问题,在后面的网络层,它建立了一个更加复杂和抽象的层级结构。包含这种多层结构(两层或更多隐含层)的网络叫做深度神经网络(deep neural network)。
当然,我没有去解释应该如何将它递归地分解成子网络。在网络中通过人工来设置权重和偏置是不切实际的。取而代之的是,我们使用学习算法来让网络能够自动的从训练数据中学习权重和偏置。1980到1990年代的研究人员尝试了使用随机梯度下降和反向传播来训练深度网络。不幸的是,除了一些特殊的结构,他们并没有取得很好的效果。虽然网络能够学习,但是学习速度非常缓慢,不适合在实际中使用。

