
用简单的神经网络识别手写数字
分割为6张小图像

我们人类能够很容易地解决这个分割问题,但是让计算机去正确地分割图像是一件极具挑战的任务。当图像被分割之后,接下来的任务就是如何识别每个独立的手写数字。举个例子来说,我们想要程序去识别上述图像中的第一个数字,
结果是5。
我们将把精力集中在实现程序去解决第二个问题,即如何正确分类每个单独的手写数字。因为事实证明,只要你解决了数字分类的问题,分割问题相对来说不是那么困难。分割问题的解决方法有很多。一种方法是尝试不同的分割方式,用数字分类器对每一个切分片段打分。如果数字分类器对每一个片段的置信度都比较高,那么这个分割方式就能得到较高的分数;如果数字分类器在一或多个片段中出现问题,那么这种分割方式就会得到较低的分数。这种方法的思想是,如果分类器有问题,那么很可能是由于图像分割出错导致的。这种思想以及它的变种能够比较好地解决分割问题。因此,与其关心分割问题,我们不如把精力集中在设计一个神经网络来解决更有趣、更困难的问题,即手写数字的识别。
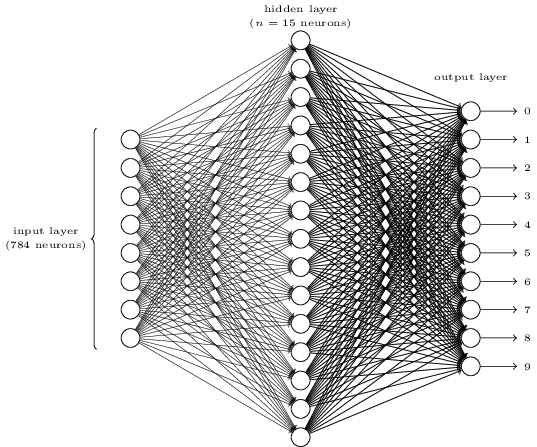
这个网络的输入层是对输入像素编码的神经元。正如我们在下一节将要讨论的,我们的训练数据是一堆乘手写数字的位图,因此我们的输入层包含了个神经元。为了方便起见,我在上图中没有完全画出个输入神经元。输入的像素点是其灰度值,代表白色,代表黑色,中间值表示不同程度的灰度值。
网络的第二层是隐层。我们为隐层设置了个神经元,我们会实验的不同取值。在这个例子中我们只展现了一个规模较小的隐层,它仅包含了个神经元。
网络的输出层包含了10个神经元。如果第一个神经元被激活,例如输出,然后我们可以推断出这个网络认为这个数字是。如果第二层被激活那么我们可以推断出这个网络认为这个数字是。以此类推。更精确一些的表述是,我们把输出层神经元依次标记为到,我们要找到哪一个神经元拥有最高的激活值。如果号神经元有最高值,那么我们的神经网络预测输入数字是。对其它的神经元也如此。
你可能会好奇为什么我们用个输出神经元。毕竟我们的任务是能让神经网络告诉我们哪个数字()能和输入图片匹配。一个看起来更自然的方式就是使用个输出神经元,把每一个当做一个二进制值,结果取决于它的输出更靠近还是。四个神经元足够编码这个问题了,因为大于种可能的输入。为什么我们反而要用个神经元呢?这样做难道效率不低吗?最终的判断是基于经验主义的:我们可以实验两种不同的网络设计,结果证明对于这个特定的问题而言,个输出神经元的神经网络比个的识别效果更好。但是令我们好奇的是为什么使用个输出神经元的神经网络更有效呢。有没有什么启发性的思考能提前告诉我们用个输出编码比使用个输出编码更有好呢?
为了理解为什么我们这么做,我们需要从根本原理上理解神经网络究竟在做些什么。首先考虑有个神经元的情况。我们首先考虑第一个输出神经元,它告诉我们一个数字是不是。它能那么做是因为可以权衡从隐藏层来的信息。隐藏层的神经元在做什么呢?假设隐藏层的第一个神经元只是用于检测如下的图像是否存在:

正如你所猜到的那样,这四个图像拼到一起就组成了数字 :
如果所有这四个隐藏层的神经元被激活那么我们就可以推断出这个数字是。当然,这不是我们推断出的唯一方式——我们能通过很多其他合理的方式得到 (举个例子来说,通过上述图像的转换,或者稍微变形)。但至少在这个例子中我们可以推断出输入的数字是 。
假设神经网络以上述方式运行,我们可以给出一个貌似合理的理由去解释为什么用个输出而不是个。如果我们有个输出,那么第一个输出神经元将会尽力去判断数字的最高有效位是什么。把数字的最高有效位和数字的形状联系起来并不是一个简单的问题。很难想象出有什么恰当的历史原因,一个数字的形状要素会和一个数字的最高有效位有什么紧密联系。
上面我们说的只是一个启发性的思考。没有什么理由表明这个三层的神经网络必须按照我所描述的方式运行,即隐藏层是用来探测数字的组成形状。可能一个聪明的学习算法将会找到一些合适的权重能让我们仅仅用个输出神经元就行。但是这个启发式的思考通常很有效,它会节省你大量时间去设计一个好的神经网络结构。

