
数据压缩
从软件系统层面来讲,对于数据库等特殊领域,需要对存储在磁盘等介质上的海量数据进行高频访问。此时,磁盘 I/O 就成为整体性能的一个关键节点。数据压缩后存储到磁盘,可以大大减小 I/O 需求,系统能够提供更高的性能和吞吐量。
衡量压缩效果的是压缩率(Compression ratio),是指压缩后大小与压缩前大小的比值,该值越小,表示压缩效果越好。影响压缩率的关键因素有两个:
- 压缩算法:压缩算法领域也没有“银弹”,不同的压缩算法都是在速度和压缩率之间进行取舍,更快的算法通常意味着更大的压缩率
SequoiaDB 巨杉数据库内部使用 BSON 结构来存储数据,这是一种类 JSON 的二进制编码格式。BSON 结构的一个重要特点是自描述,每条记录都包含完整的字段信息,因此数据中存在着大量的重复信息,这种特点使数据压缩具备了必要性与可行性。
- LZW 压缩
使用数据压缩的方法很简单,在创建集合时,通过参数 Compressed 及 CompressionType 打开压缩并指定压缩类型即可:
在 SequoiaDB 中,Snappy 压缩算法具有很高的压缩与解压速度,CPU 等资源开销比 LZW 低。压缩与解压就是数据的处理和迁移过程:原始记录在内存中被压缩,然后存入文件中,或者从文件中读取压缩的记录,在内存中解压使用。
LZW 压缩
基于集合中的记录通常具有相似的结构和值这一典型特征,SequoiaDB 中的 LZW 压缩算法使用一定规模的真实记录作为样本数据,分析其中的数据重复情况,提取出最有效的压缩字典,使用该压缩字典对新产生的数据进行压缩或对压缩数据进行解压。压缩字典也与集合数据一起持久化存储到数据文件中,节点重启后也可正常使用。
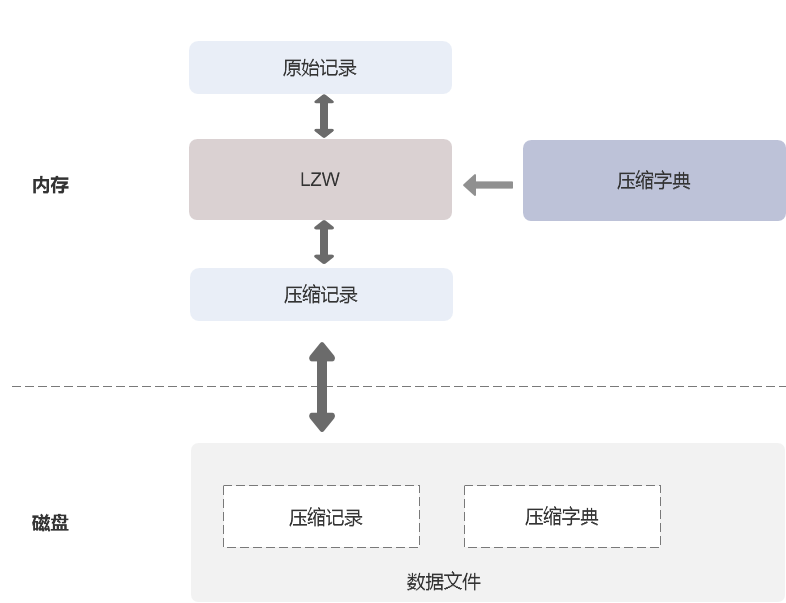
数据库实例后台运行着一个字典构造器线程。创建集合时指定开启 LZW 压缩后,字典构造器的任务队列会添加一个新的字典创建任务。当开始处理一个集合的字典生成任务时,就从该集合中提取样本数据进行分析,并最终生成压缩字典,持久化存储到文件中。如果发现集合的样本数据过少(少于64MB 或 100 条记录),则会暂时挂起该任务,将它放到任务队列尾部,下一次轮询到它时再次进行处理。
集群中各数据库实例的字典构造器都是独立的,因此即使是在同一个分区组内的主节点和从节点上,同一个集合生成的字典也可能是不一样的,压缩之后的数据也不一样,但解压出来的数据是一致的。 一般而言,推荐使用 LZW 压缩算法。虽然 LZW 压缩算法的速度不及 Snappy,且 CPU 开销相对较高,但由于 LZW 算法在更大范围样本数据的基础上生成了更有效的压缩字典,在典型的数据库应用场景中,其压缩效果通常远胜于 Snappy 压缩,具备更好的适用性。

