
数据挖掘算法学习(八)Adaboost算法
算法概述
1、先通过对N个训练样本的学习得到第一个弱分类器;2、将分错的样本和其他的新数据一起构成一个新的N个的训练样本,通过对这个样本的学习得到第二个弱分类器;3、将1和2都分错了的样本加上其他的新样本构成另一个新的N个的训练样本,通过对这个样本的学习得到第三个弱分类器4、最终经过提升的强分类器。即某个数据被分为哪一类要由各分类器权值决定。
与boosting算法比较
与Boosting算法不同的是,AdaBoost算法不需要预先知道弱学习算法学习正确率的下限即弱分类器的误差,并且最后得到的强分类器的分类精度依赖于所有弱分类器的分类精度,这样可以深入挖掘弱分类器算法的能力。
算法步骤
具体步骤如下:
一.样本
二.初始化训练样本
实例详解
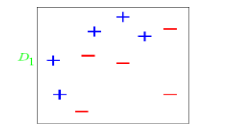
图中“+”和“-”表示两种类别。我们用水平或者垂直的直线作为分类器进行分类。
算法开始前默认均匀分布D,共10个样本,故每个样本权值为0.1.
第一次分类:
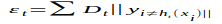 计算可得
计算可得
分类器权重:
然后根据算法把错分点的权值变大。对于正确分类的7个点,权值不变,仍为0.1,对于错分的3个点,权值为:
第二次分类:
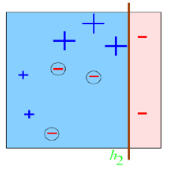
如图所示,有3个"-"分类错误。上轮分类后权值之和为:0.1_7+0.2333_3=1.3990
分类误差:e2=0.1*3/1.3990=0.2144
分类器权重
错分的3个点权值为:D2=0.1*(1-0.2144)/0.2144=0.3664
第三次分类:
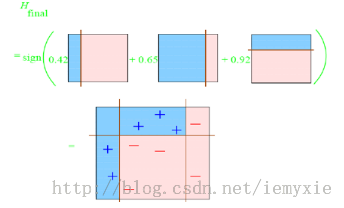
同上步骤可求得: ;a3=0.9223;
最终的强分类器即为三个弱分类器的叠加,如下图所示:
分类器权值调整的原因
由公式可以看到,权值是关于误差的表达式。每次迭代都会提高错分点的权值,当下一次分类器再次错分这些点之后,会提高整体的错误率,这样就导致分类器权值变小,进而导致这个分类器在最终的混合分类器中的权值变小,也就是说,Adaboost算法让正确率高的分类器占整体的权值更高,让正确率低的分类器权值更低,从而提高最终分类器的正确率。
算法优缺点
优点
1)Adaboost是一种有很高精度的分类器2)可以使用各种方法构建子分类器,Adaboost算法提供的是框架3)当使用简单分类器时,计算出的结果是可以理解的。而且弱分类器构造极其简单4)简单,不用做特征筛选5)不用担心overfitting(过度拟合)
缺点
1)容易受到噪声干扰,这也是大部分算法的缺点
2)训练时间过长
3)执行效果依赖于弱分类器的选择
SQL实现
以上是博主最近用SQL实现的Adaboost算法的部分代码。数据库表以后整理一下再贴。Ubuntu不稳定啊,死机两次了。。编辑的博客都没了。。累觉不爱。。
个人疑问
上文中的缺点提到,Adaboost算法的效果依赖于弱分类器的选择,那么面对巨大的待分类数据时,如何选择弱分类呢?有没有什么原则。博主依旧在探索中,找到答案的话会在这里更新。
推荐资料:由Adaboost算法创始人Freund和Schapire写的关于Adaboost算法的文档,我已经上传。

