
这是什么意思呢?
首先我们回顾几个基础的消息系统术语:
Kafka将消息源放在称为topics的归类组维护
我们将发布消息到Kafka topic上的处理程序称之为producers
Kafka采用集群方式运行,集群由一台或者多台服务器构成,每个机器被称之为一个broker
(译者注:这些基本名词怎么翻译都觉着怪还是尽量理解下原文)
所以高度概括起来,producers(生产者)通过网络将messages(消息)发送到Kafka机器,然后由集群将这些消息提供给consumers(消费者),如下图所示:
Clients(客户端)和Servers(服务器)通过一个简单的、高效的进行交互。官方为Kafka提供一个Java客户端,但更多其他语言的客户端可以在这里找到。
Let’s first dive into the high-level abstraction Kafka provides—the topic.
首先我们先来深入Kafka提供的关于Topic的高层抽象。
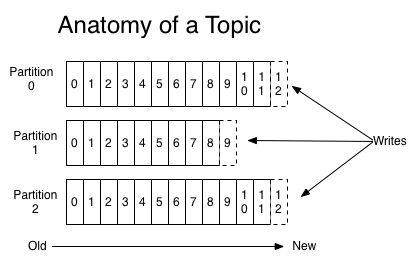
每个partition(分区)是一个有序的、不可修改的、消息组成的队列;这些消息是被不断的appended(追加)到这个commit log(提交日志文件)上的。在这些patitions之中的每个消息都会被赋予一个叫做offset的顺序id编号,用来在partition之中唯一性的标示这个消息。
Kafka集群会保存一个时间段内所有被发布出来的信息,无论这个消息是否已经被消费过,这个时间段是可以配置的。比如日志保存时间段被设置为2天,那么2天以内发布的消息都是可以消费的;而之前的消息为了释放空间将会抛弃掉。Kafka的性能与数据量不相干,所以保存大量的消息数据不会造成性能问题。
实际上Kafka关注的关于每个消费者的元数据信息也基本上仅仅只有这个消费者的”offset”也就是它访问到了log的哪个位置。这个offset是由消费者控制的,通常情况下当消费者读取信息时这个数值是线性递增的,但实际上消费者可以自行随意的控制这个值从而随意控制其消费信息的顺序。例如,一个消费者可以将其重置到更早的时间来实现信息的重新处理。
这些特性组合起来就意味着Kafka消费者是非常低消耗,它们可以随意的被添加或者移除而不会对集群或者其他的消费者造成太多的干扰。例如,你可以通过我们的命令行工具”tail”(译者注:Linux的tail命令的意思)任何消息队列的内容,这不会对任何已有的消费者产生任何影响。
对log进行分区主要是为了以下几个目的:第一、这可以让log的伸缩能力超过单台服务器上线,每个独立的partition的大小受限于单台服务器的容积,但是一个topic可以有很多partition从而使得它有能力处理任意大小的数据。第二、在并行处理方面这可以作为一个独立的单元。
log的partition被分布到Kafka集群之中;每个服务器负责处理彼此共享的partition的一部分数据和请求。每个partition被复制成指定的份数散布到机器之中来提供故障转移能力。
对于每一个partition都会有一个服务器作为它的”leader”并且有零个或者多个服务器作为”followers”。leader服务器负责处理关于这个partition所有的读写请求,followers服务器则被动的复制leader服务器。如果有leader服务器失效,那么followers服务器将有一台被自动选举成为新的leader。每个服务器作为某些partition的leader的同时也作为其它服务器的follower,从而实现了集群的负载均衡。
生产者将数据发布到它们选定的topics上。生产者负责决定哪个消息发送到topic的哪个partition上。这可以通过简单的轮询策略来实现从而实现负载均衡,也可以通过某种语义分区功能实现(基于某个消息的某个键)。关于partition功能的应用将在后文进一步介绍。
通常消息通信有两种模式:队列模式和订阅模式。在中一组消费者可能是从一个服务器读取消息,每个消息被发送给其中一个消费者。在订阅模式,消息被广播给所有的消费者。Kafka提供了一个抽象,把consumer group的所有消费者视为同一个抽象的消费者。
每个消费者都有一个自己的消费组名称标示,每一个发布到topic上的消息会被投递到每个订阅了此topic的消费者组的某一个消费者(译者注:每组都会投递,但每组都只会投递一份到某个消费者)。这个被选中的消费者实例可以在不同的处理程序中或者不同的机器之上。
如果所有的消费者实例都采用不同的消费组,那么真个结构就是订阅模式,每一个消息将被广播给每一个消费者。
通常来说,我们发现在实际应用的场景,常常是一个topic有数量较少的几个消费组订阅,每个消费组都是一个逻辑上的订阅者。每个消费组由由很多消费者实例构成从而实现横向的扩展和故障转移。其实这也是一个消息订阅模式,无非是消费者不再是一个单独的处理程序而是一个消费者集群。
一个两节点的kafka集群支持的2个消费组的四个分区(P0-P3)。消费者A有两个消费者实例,消费者B有四个消费者实例。
kafka还提供了相比传统消息系统更加严格的消息顺序保证。
传统的消息队列在服务器上有序的保存消息,当有多个消费者的时候消息也是按序发送消息。但是因为消息投递到消费者的过程是异步的,所以消息到达消费者的顺序可能是乱序的。这就意味着在并行计算的场景下,消息的有序性已经丧失了。消息系统通常采用一个“排他消费者”的概念来规避这个问题,但这样就意味着失去了并行处理的能力。
Kafka在这一点上做的更优秀。Kafka有一个Topic中按照partition并行的概念,这使它即可以提供消息的有序性担保,又可以提供消费者之间的负载均衡。这是通过将Topic中的partition绑定到消费者组中的具体消费者实现的。通过这种方案我们可以保证消费者是某个partition唯一消费者,从而完成消息的有序消费。因为Topic有多个partition所以在消费者实例之间还是负载均衡的。注意,虽然有以上方案,但是如果想担保消息的有序性那么我们就不能为一个partition注册多个消费者了。
Kafka仅仅提供提供partition之内的消息的全局有序,在不同的partition之间不能担保。partition的消息有序性加上可以按照指定的key划分消息的partition,这基本上满足了大部分应用的需求。如果你必须要实现一个全局有序的消息队列,那么可以采用Topic只划分1个partition来实现。但是这就意味着你的每个消费组只有有唯一的一个消费者进程。
在上层Kafka提供一下可靠性保证:
生产者发送到Topic某个partition的消息都被有序的追加到之前发送的消息之后。意思就是如果一个消息M1、M2是同一个生产者发送的,先发送的M1那么M1的offse就比M2更小也就是更早的保存在log中。
对于特定的消费者,它观察到的消息的顺序与消息保存到log中的顺序一致。
更多关于可靠性保证的细节,将会在后续的本文档设计章节进行讨论。

