
Inside each level (except level 0), data is range partitioned into multiple SST files:
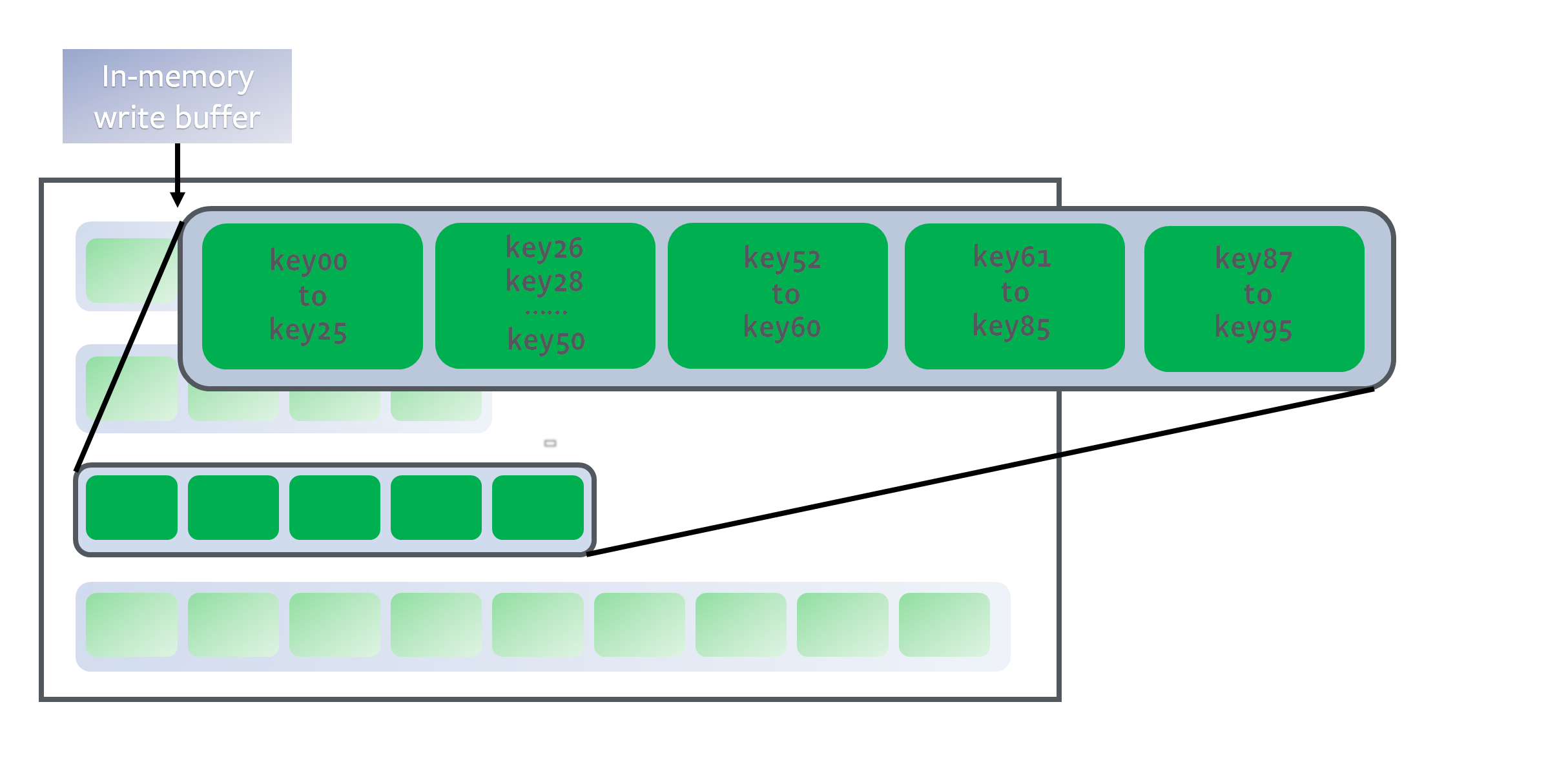
The level is a sorted run because keys in each SST file are sorted (See as an example). To identify a position for a key, we first binary search the start/end key of all files to identify which file possibly contains the key, and then binary search inside the file to locate the exact position. In all, it is a full binary search across all the keys in the level.
All non-0 levels have target sizes. Compaction’s goal will be to restrict data size of those levels to be under the target. The size targets are usually exponentially increasing:
Compactions
Compaction triggers when number of L0 files reaches level0_file_num_compaction_trigger, files of L0 will be merged into L1. Normally we have to pick up all the L0 files because they usually are overlapping:
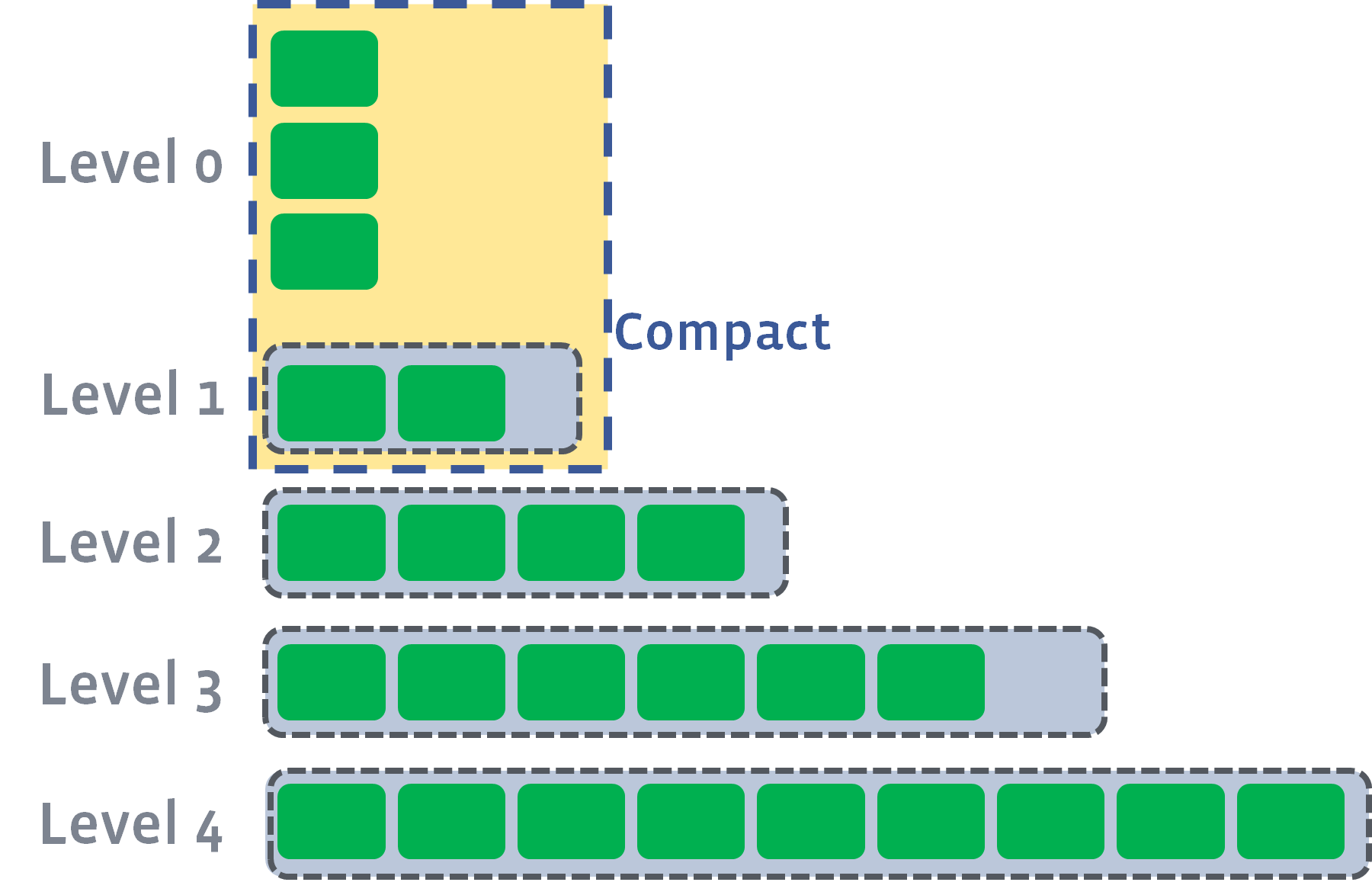
After the compaction, it may push the size of L1 to exceed its target:
In this case, we will pick at least one file from L1 and merge it with the overlapping range of L2. The result files will be placed in L2:
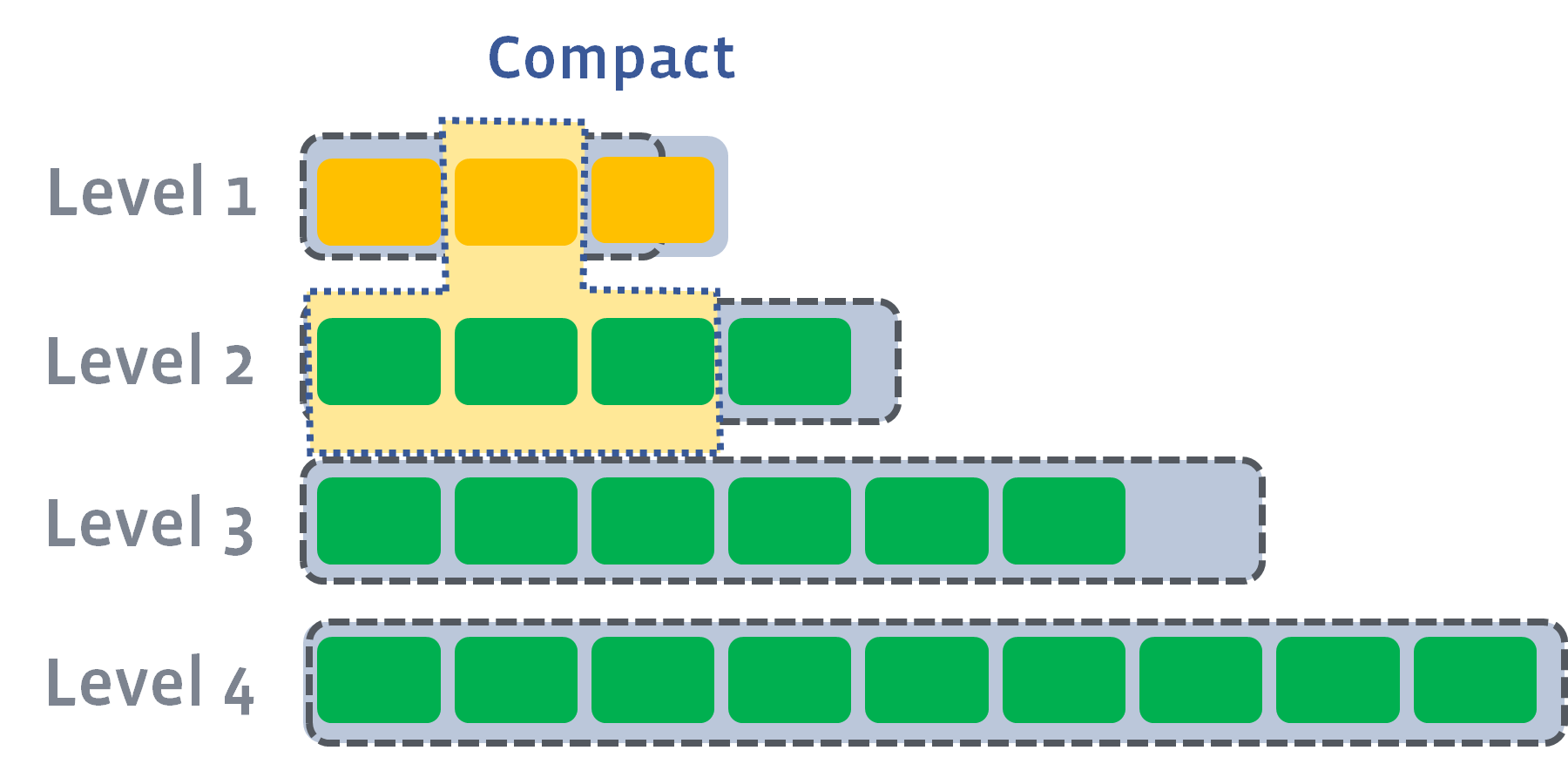
If the results push the next level’s size exceeds the target, we do the same as previously — pick up a file and merge it into the next level:
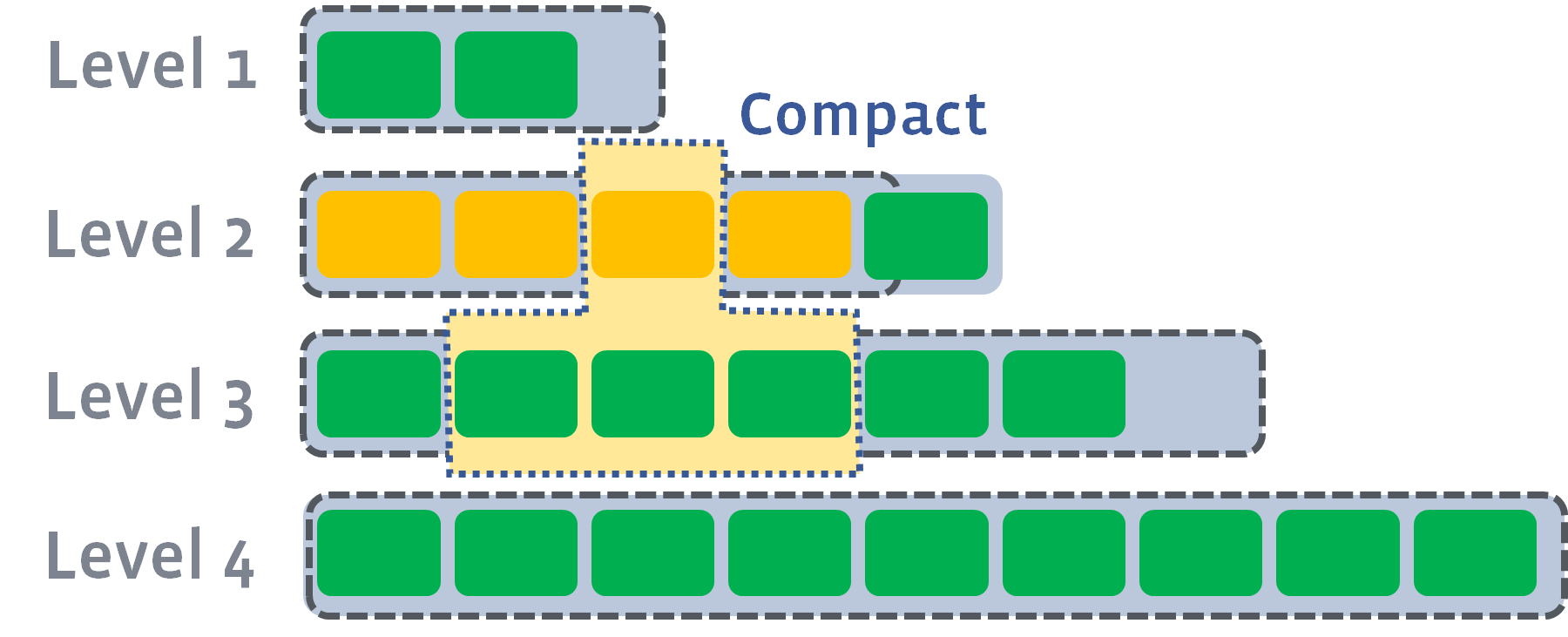
and then
Multiple compactions can be executed in parallel if needed:
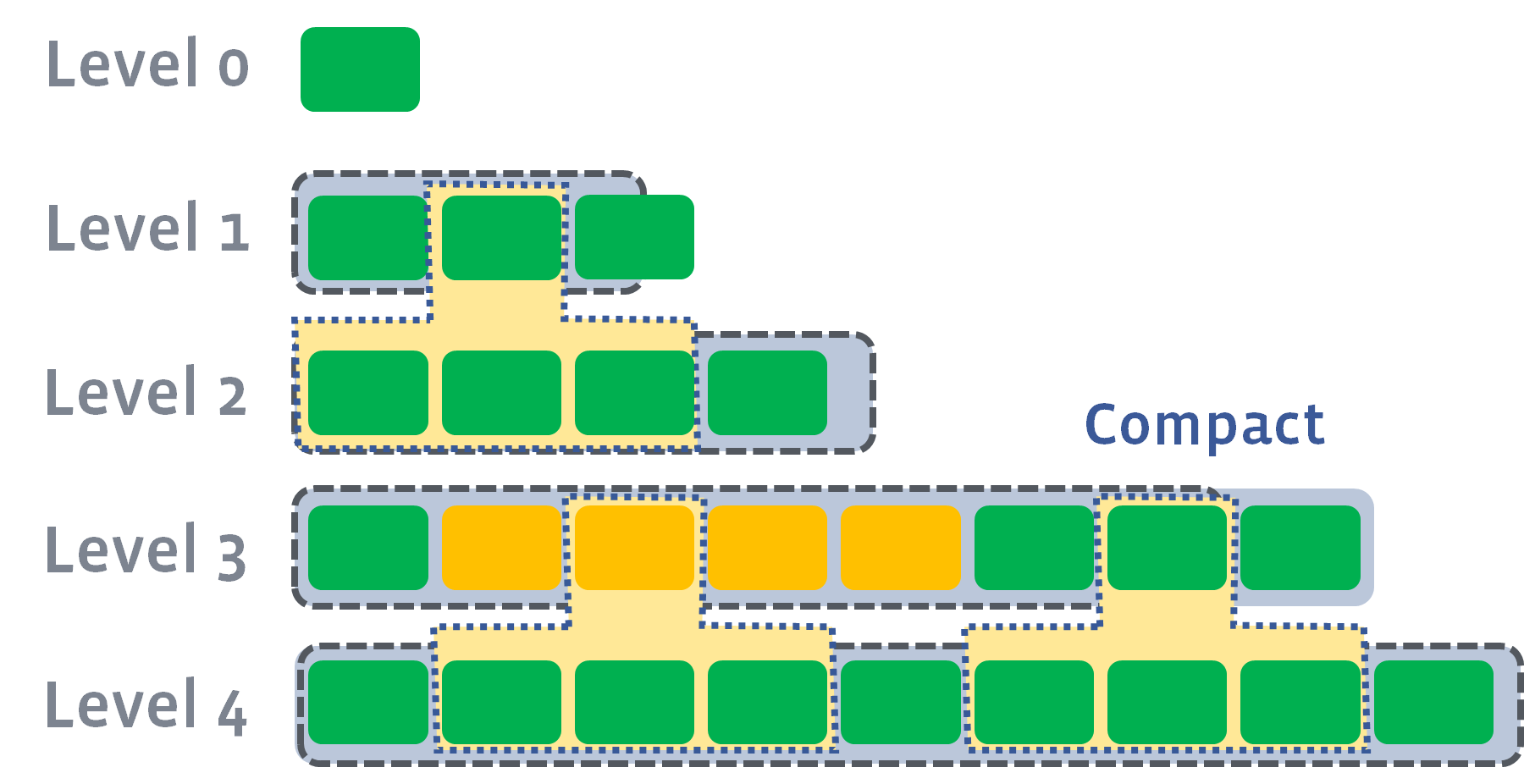
Maximum number of compactions allowed is controlled by max_background_compactions.
However, L0 to L1 compaction cannot be parallelized. In some cases, it may become a bottleneck that limit the total compaction speed. In this case, users can set max_subcompactions to more than 1. In this case, we’ll try to partition the range and use multiple threads to execute it:
When multiple levels trigger the compaction condition, RocksDB needs to pick which level to compact first. A score is generated for each level:
For non-zero levels, the score is total size of the level divided by the target size. If there are already files picked that are being compacted into the next level, the size of those files is not included into the total size, because they will soon go away.
We compare the score of each level, and the level with highest score takes the priority to compact.
Which file(s) to compact from the level are explained in Choose Level Compaction Files.
Levels’ Target Size
For example, if max_bytes_for_level_base = 16384, max_bytes_for_level_multiplier = 10 and max_bytes_for_level_multiplier_additional is not set, then size of L1, L2, L3 and L4 will be 16384, 163840, 1638400, and 16384000, respectively.
Target size of the last level (num_levels-1) will always be actual size of the level. And then Target_Size(Ln-1) = Target_Size(Ln) / max_bytes_for_level_multiplier. We won’t fill any level whose target will be lower than max_bytes_for_level_base / max_bytes_for_level_multiplier . These levels will be kept empty and all L0 compaction will skip those levels and directly go to the first level with valid target size.
For example, if max_bytes_for_level_base is 1GB, num_levels=6 and the actual size of last level is 276GB, then the target size of L1-L6 will be 0, 0, 0.276GB, 2.76GB, 27.6GB and 276GB, respectively.
This is to guarantee a stable LSM-tree structure, which can’t be guaranteed if level_compaction_dynamic_level_bytes is false. For example, in the previous example:
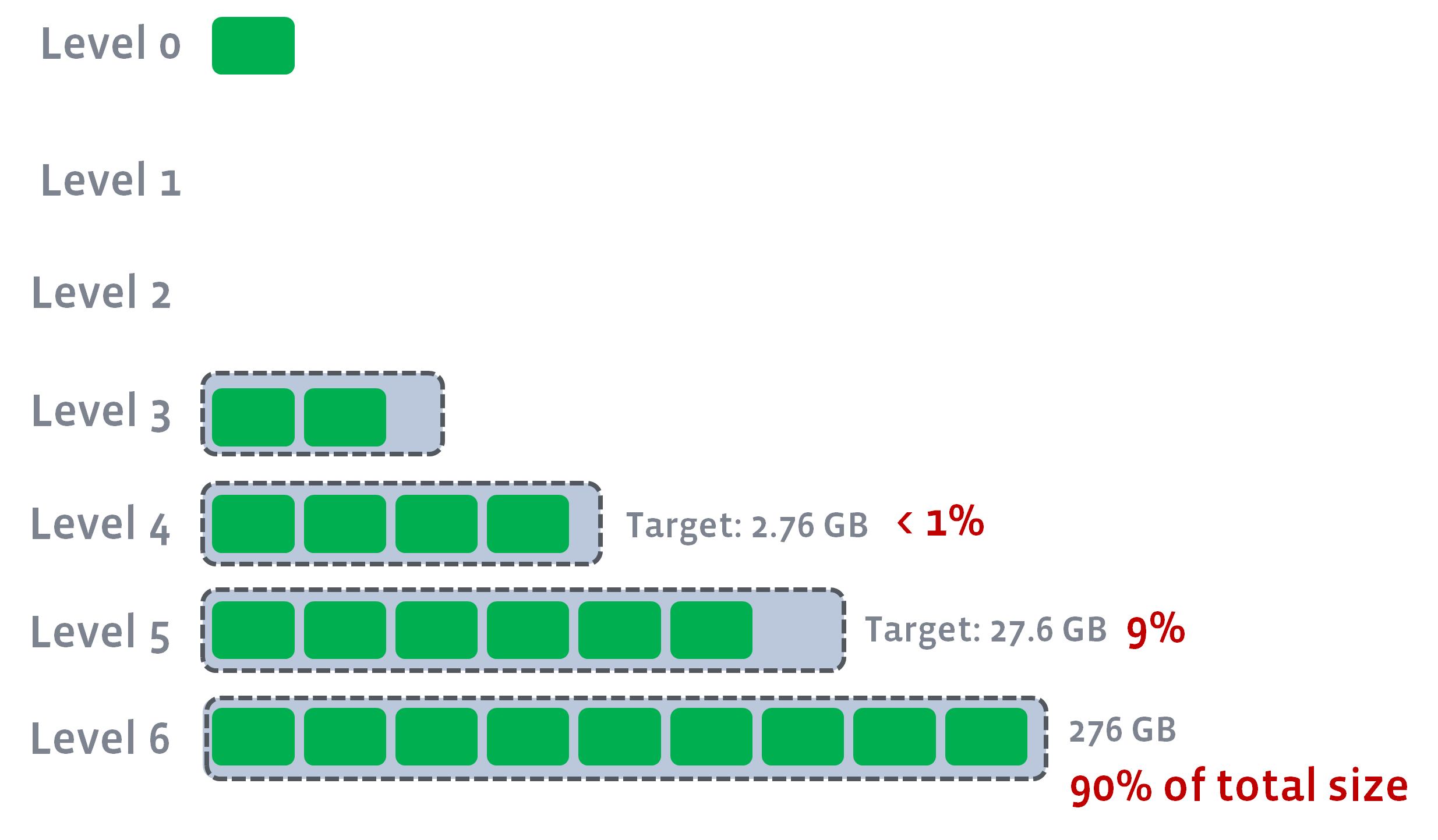
We can guarantee 90% of data is stored in the last level, 9% data in the second last level. There will be multiple benefits to it.
Sometimes writes are heavy, temporarily or permanently, so that number of L0 files piled up before they can be compacted to lower levels. When it happens, the behavior of leveled compaction changes:
Intra-L0 Compaction
Too many L0 files hurt read performance in most queries. To address the issue, RocksDB may choose to compact some L0 files together to a larger file. This sacrifices write amplification by one but may significantly improve read amplification in L0 and in turn increase the capability RocksDB can hold data in L0. This would generate other benefits which would be explained below. Additional write amplification of 1 is far smaller than the usual write amplification of leveled compaction, which is often larger than 10. So we believe it is a good trade-off. Maximum size of Intra-L0 compaction is also bounded by options.max_compaction_bytes. If the option takes a reasonable value, total L0 size will still be bounded, even with Intra-L0 files.
Adjust level targets
If total L0 size grows too large, it can be even larger than target size of L1, or even lower levels. It doesn’t make sense to continue following this configured targets for each level. Instead, for dynamic level, target levels are adjusted. Size of L1 will be adjusted to actual size of L0. And all levels between L1 and the last level will have adjusted target sizes, so that levels will have the same multiplier. The motivation is to make compaction down to lower levels to happen slower. If data stuck in L0->L1 compaction, it is wasteful to still aggressively compacting lower levels, which competes I/O with higher level compactions.
For example, if configured multiplier is 10, configured base level size is 1GB, and actual L1 to L4 size is 640MB, 6.4GB, 64GB, 640GB, accordingly. If a spike of writes come, and push total L0 size up to 10GB. L1 size will be adjusted to 10GB, and size target of L1 to L4 becomes 10GB, 40GB, 160GB, 640GB. If it is a temporary spike, then actual file size of lower levels are still close to the previous size, which means lower level compaction almost stops, and all the resource is used for L0 => L1 and L1 => L2 compactions, so that it can clear L0 files sooner. In case the high write rate becomes permanent. The adjusted targets’s write amplification (expected 14) is better than the configured one (expected 34), so it’s a good move.
The goal for this feature is for leveled compaction to handle temporary spike of writes more smoothly. Note that leveled compaction still cannot efficiently handle write rate that is too much higher than capacity based on the configuration. Works on going to further improve it.
A file could exist in the LSM tree without going through the compaction process for a really long time if there are no updates to the data in the file’s key range. For example, in certain use cases, the keys are “soft deleted” — set the values to be empty instead of actually issuing a Delete. There might not be any more writes to this “deleted” key range, and if so, such data could remain in the LSM for a really long time resulting in wasted space.
A dynamic ttl column-family option has been introduced to solve this problem. Files (and, in turn, data) older than TTL will be scheduled for compaction when there is no other background work. This will make the data go through the regular compaction process and get rid of old unwanted data. This also has the (good) side-effect of all the data in the non-bottommost level being newer than ttl, and all data in the bottommost level older than ttl. Note that it could lead to more writes as RocksDB would schedule more compactions.

