
概述
simhash算法
simhash是由Charikar在2002年提出来的,论文名为《Similarity estimation techniques from rounding algorithms》。Google基于simhash在海量网页中进行相似度计算并去重。通常对比两个文档是否相同时,会计算对应的hash值,常见的算法包括md5和sha256。实际使用中,对于检测文档是否被篡改时,使用hash值具有不错的表现。但是当文档内容因为修改少许文字,插入广告甚至只是修改了标点符合和错别字,都会导致hash值改变,可是文档的核心内容并未发生改变。如何使用数学的方法表征这种文档相似性呢?simhash的设计初衷就是使用一种所谓局部hash的方法,可以既可以敏感的识别文档的少许修改又可以识别出文档的大多数内容相同。
simhash的一种典型实现就是将一个文档最后转换成一个64位的字节的特征字或者说simhash值,然后判断重复只需要判断他们的特征字的距离是不是小于3,就可以判断两个文档是否相似。这个距离使用海明距离,即两个simhash值取异或后二进制中1的个数。大家可以结合自身业务特点修改simhash值的位数以及判断文档相似性的海明距离的值。
如图所示,计算6位simhash值典型的实现算法为:
- 将Doc分词和计算权重,抽取出n个(关键词,权重)对,即图中的(feature, weight)
- 计算关键词的hash,生成图中的(hash,weight),并将hash和weight相乘,这一过程是对hash值加权
- 将hash和weight相乘的值相加,比如图中的[13, 108, -22, -5, -32, 55],并最终转换成simhash值110001,转换的规则为正数为1负数为0
simhash具有多种实现,常用的一种已经部署在pip源上了,直接安装即可。
有兴趣的读者也可以使用源码安装。
python setup.pypython setup.py install
数据集
数据集依然使用搜狗实验室提供的”搜狐新闻数据”,该数据来自搜狐新闻2012年6月—7月期间国内,国际,体育,社会,娱乐等18个频道的新闻数据,提供URL和正文信息。 对应的网址为:
为了处理方便,我们提取其中前1万条的正文信息,保存到如下文件中:
为了避免开发环境的编码方式对结果的影响,设置环境的默认编码方式为utf8.
reload(sys)sys.setdefaultencoding('utf8')
加载加载搜狐新闻语料.
选择其第88篇文章为测试文章,在剩下的语料中寻找与其相似的文档。
#加载搜狐新闻语料content=load_sougou_content()#设置测试文章test_news=content[88]print test_news
测试文档的内容如下:
数据清洗过程,加载我们积累的中文停用词。
def load_stopwords():with open("stopwords.txt") as F:stopwords=F.readlines()return [word.strip() for word in stopwords]
为了避免停用词的影响,清洗阶段我们从数据集中删除停用词。
计算simhash值
依次计算语料库中每条记录的simhash,并记录下与测试数据的距离。
sim=[]# 遍历语料计算simhash值hash = Simhash(news)score=test_news_hash.distance(hash)sim.append( score)
选择距离最短的6的文档和序号并打印,因为需要按照score正序排列,需要设置key参数。
for index, score in sorted(enumerate(sim), key=lambda item: item[1])[:6]:print "index:%d similarities:%f content:%s" % (index, score, content[index])
余弦距离
余弦距离,又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估他们的相似度。余弦相似度将向量根据坐标值,绘制到向量空间中,如最常见的二维空间。假设向量a、b的坐标分别为(x1,y1)、(x2,y2) ,则对应的余弦距离为:
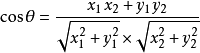
设向量 A = (A1,A2,…,An),B = (B1,B2,…,Bn) 。推广到多维:
夹角越小,余弦值越接近于1,它们的方向更加吻合,则越相似。可见余弦距离在0和1之间且约接近1说明越两者越相似。
数据集也和simhash使用相同的数据集。
数据清洗
数据清洗方式与simhash类似,只不过多了一个TFIDF处理。
词袋提取使用的是gensim的库,生成的矩阵为稀疏矩阵。
index = similarities.SparseMatrixSimilarity(tfidf[corpus], num_features=len(dictionary.keys()))sim = index[tfidf[test_news_vec]]for index, score in sorted(enumerate(sim), key=lambda item: -item[1])[:6]:
排名第一的是距离为0.965616的第88号文档,正好就是原文,排名第二的是序号为5644的文档,距离为40.907202,可以发现讲的也是垃圾回收的内容。

