
为了表示二叉树是有一些卵用的,所以今天引入二叉搜索树,近义词是二叉查找树或者二叉排序树,是一种常见并常用的数据结构。二叉搜索树整体是有序的,比如从大到小又或者从小到大,正是因为有序,所以才会利于查找。举个例子:一坨数字15、10、18、7、12、16、19,让你快速从中找到16。作为蠢货,我的第一个想法就是循环,挨个对比,啥时候对上号了,那就算找到了,然后我运算6次,找到了16。
然而,一些稍微不傻的人会考虑从中间7开始对比,这个时候会有两种选择:从7往前,从7往后。从7往前的就比较悲催了,但是从7往后的,3次就能找到16。
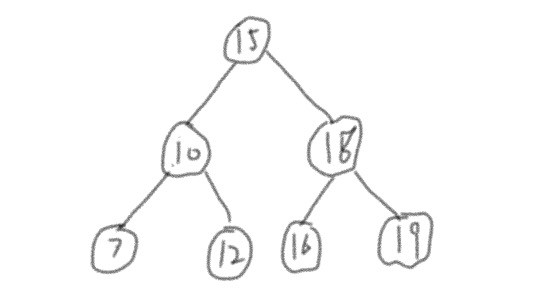
如果我们要找19,19比15大,那一定是在15的右子树上,接着15的右子树的根节点就是18,19依然比18大,然后向18的右子树进发,bingo,找到了。
通过上面的俗话和示例似乎并不能准确描述二叉搜索树(二叉排序树、二叉查找树),有时候官方语言还是要套一套的:
上面代码就是上节课完整的代码,但是,很明显由于二叉搜索树的特征,setLeft和setRight两个方法算是报废了,最起码说,是不能直接调用的。迫于无奈,不得不分析一波儿了:拿新结点的数值和原有树的根节点开始比较,比根节点大,那么往右走;比根节点小,那么往左走。然后我们将根节点的左子树或者右子树依然当作一颗独立完整的树来看待,那么,然后继续用新结点与之进行上述步骤。。。是不是闻到了一股浓重的递归味儿?
开篇吹过了,搜索二叉树一大优势就是快速查找确定数值的结点,那么是时候出来溜溜了。其实查找本身也是也是根据搜索二叉树的特征进行查找的,整个过程和添加结点是颇为相似的。依然是从根节点开始,要么find的目标结点比根节点的小,要么find的目标结点比根结点的大,小了往左走,大了往右走。无论是往左走还是往右走,我们都可以把其子树当作独立的一个树,和要find的目标依然重复上述操作,最终当要find的目标既不大于根结点也不小于根节点,也就是意味着找到该结点了。同时,我们知道一颗搜索二叉树的最小值一定是最左下角那个结点,最大值一定是最右下角那个结点,所以这两个方法应该很容易写出来,你们感受一下:
码完代码,跑一个简单的小测试。这里值得注意的一点是,如果对一个搜索二叉树进行中序遍历,那么会得到一个有序数字队列。

